 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Bounds for Gradient Methods via Discrete and Continuous Prior
Paper and Code
Jun 01, 2022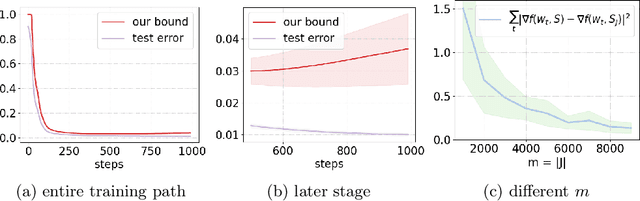
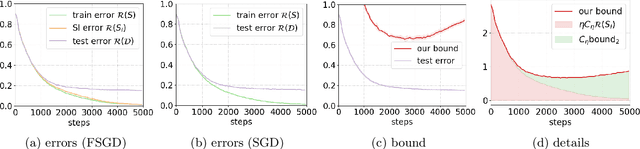
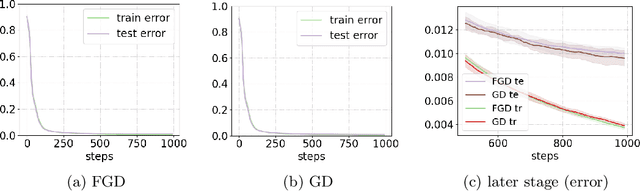
Proving algorithm-dependent generalization error bounds for gradient-type optimization methods has attracted significant attention recently in learning theory. However, most existing trajectory-based analyses require either restrictive assumptions on the learning rate (e.g., fast decreasing learning rate), or continuous injected noise (such as the Gaussian noise in Langevin dynamics). In this paper, we introduce a new discrete data-dependent prior to the PAC-Bayesian framework, and prove a high probability generalization bound of order $O(\frac{1}{n}\cdot \sum_{t=1}^T(\gamma_t/\varepsilon_t)^2\left\|{\mathbf{g}_t}\right\|^2)$ for Floored GD (i.e. a version of gradient descent with precision level $\varepsilon_t$), where $n$ is the number of training samples, $\gamma_t$ is the learning rate at step $t$, $\mathbf{g}_t$ is roughly the difference of the gradient computed using all samples and that using only prior samples. $\left\|{\mathbf{g}_t}\right\|$ is upper bounded by and and typical much smaller than the gradient norm $\left\|{\nabla f(W_t)}\right\|$. We remark that our bound holds for nonconvex and nonsmooth scenarios. Moreover, our theoretical results provide numerically favorable upper bounds of testing errors (e.g., $0.037$ on MNIST). Using a similar technique, we can also obtain new generalization bounds for certain variants of SGD. Furthermore, we study the generalization bounds for gradient Langevin Dynamics (GLD). Using the same framework with a carefully constructed continuous prior, we show a new high probability generalization bound of order $O(\frac{1}{n} + \frac{L^2}{n^2}\sum_{t=1}^T(\gamma_t/\sigma_t)^2)$ for GLD. The new $1/n^2$ rate is due to the concentration of the difference between the gradient of training samples and that of the prior.