 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
Paper and Code
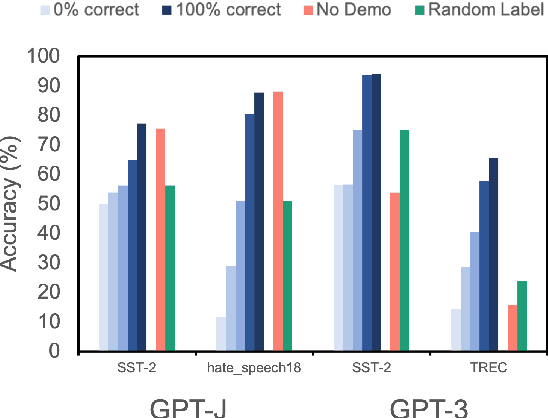
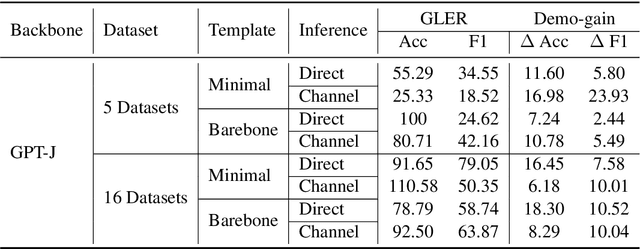
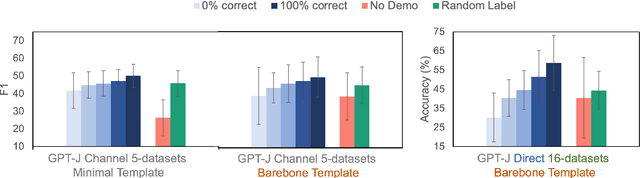
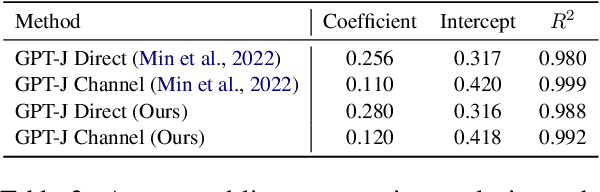
Despite recent explosion in research interests, in-context learning and the precise impact of the quality of demonstrations remain elusive. While, based on current literature, it is expected that in-context learning shares a similar mechanism to supervised learning, Min et al. (2022) recently reported that, surprisingly, input-label correspondence is less important than other aspects of prompt demonstrations. Inspired by this counter-intuitive observation, we re-examine the importance of ground truth labels on in-context learning from diverse and statistical points of view. With the aid of the newly introduced metrics, i.e., Ground-truth Label Effect Ratio (GLER), demo-gain, and label sensitivity, we find that the impact of the correct input-label matching can vary according to different configurations. Expanding upon the previous key finding on the role of demonstrations, the complementary and contrastive results suggest that one might need to take more care when estimating the impact of each component in in-context learning demonstrations.