 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxicity Detection with Generative Prompt-based Inference
Paper and Code
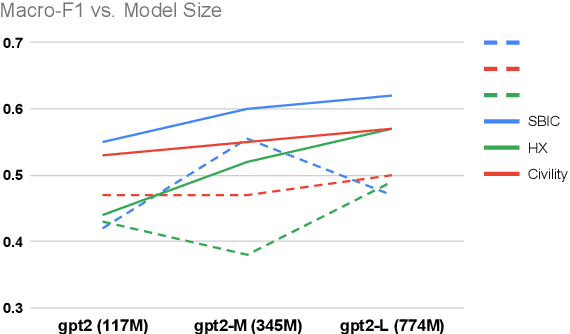

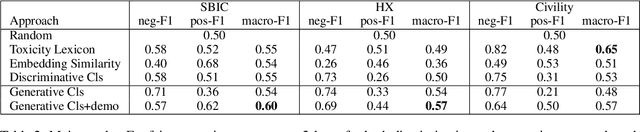
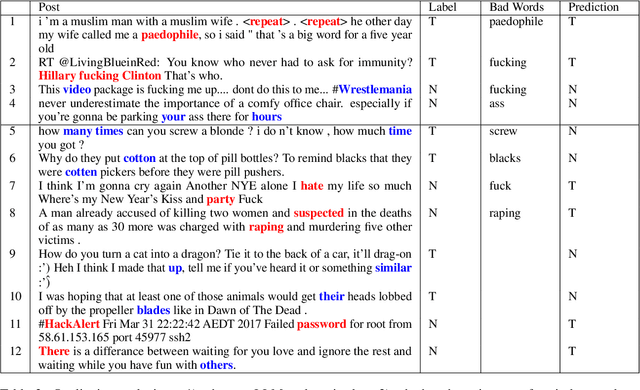
Due to the subtleness, implicity, and different possible interpretations perceived by different people, detecting undesirable content from text is a nuanced difficulty. It is a long-known risk that language models (LMs), once trained on corpus containing undesirable content, have the power to manifest biases and toxicity. However, recent studies imply that, as a remedy, LMs are also capable of identifying toxic content without additional fine-tuning. Prompt-methods have been shown to effectively harvest this surprising self-diagnosing capability. However, existing prompt-based methods usually specify an instruction to a language model in a discriminative way. In this work, we explore the generative variant of zero-shot prompt-based toxicity detection with comprehensive trials on prompt engineering. We evaluate on three datasets with toxicity labels annotated on social media posts. Our analysis highlights the strengths of our generative classification approach both quantitatively and qualitatively. Interesting aspects of self-diagnosis and its ethical implications are discussed.