 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace2Text revisited: Improved data set and baseline results
Paper and Code
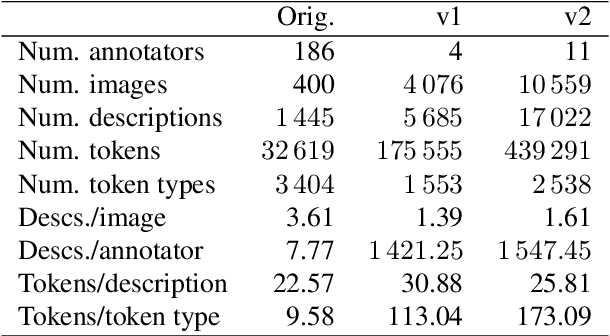

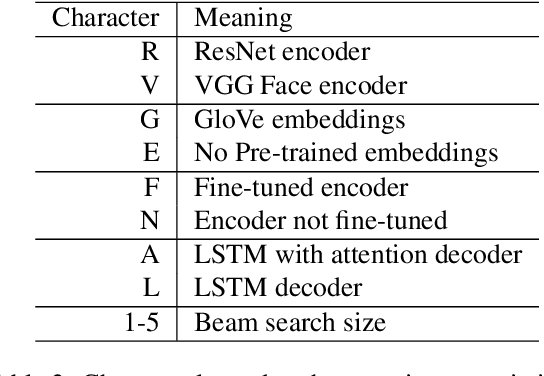
Current image description generation models do not transfer well to the task of describing human faces. To encourage the development of more human-focused descriptions, we developed a new data set of facial descriptions based on the CelebA image data set. We describe the properties of this data set, and present results from a face description generator trained on it, which explores the feasibility of using transfer learning from VGGFace/ResNet CNNs. Comparisons are drawn through both automated metrics and human evaluation by 76 English-speaking participants. The descriptions generated by the VGGFace-LSTM + Attention model are closest to the ground truth according to human evaluation whilst the ResNet-LSTM + Attention model obtained the highest CIDEr and CIDEr-D results (1.252 and 0.686 respectively). Together, the new data set and these experimental results provide data and baselines for future work in this area.