 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling A Single MR Modality
Paper and Code
May 10, 2022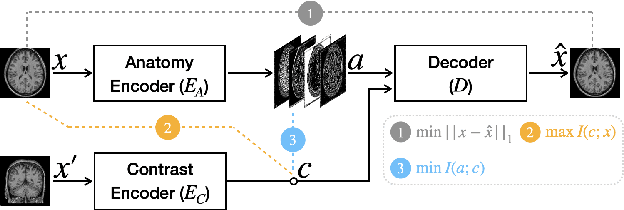
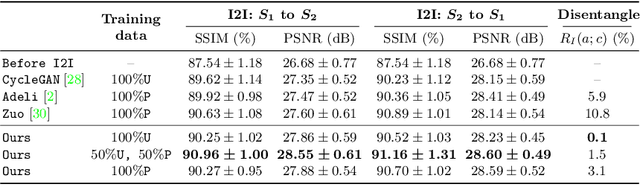
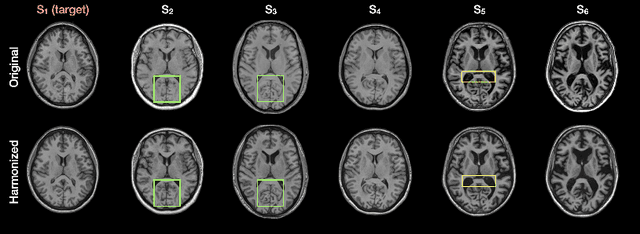
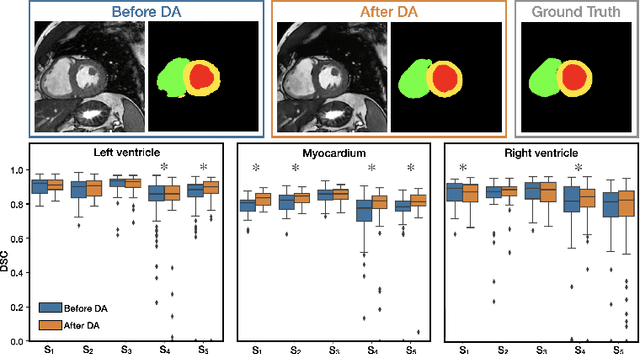
Disentangling anatomical and contrast information from medical images has gained attention recently, demonstrating benefits for various image analysis tasks. Current methods learn disentangled representations using either paired multi-modal images with the same underlying anatomy or auxiliary labels (e.g., manual delineations) to provide inductive bias for disentanglement. However, these requirements could significantly increase the time and cost in data collection and limit the applicability of these methods when such data are not available. Moreover, these methods generally do not guarantee disentanglement. In this paper, we present a novel framework that learns theoretically and practically superior disentanglement from single modality magnetic resonance images. Moreover, we propose a new information-based metric to quantitatively evaluate disentanglement. Comparisons over existing disentangling methods demonstrate that the proposed method achieves superior performance in both disentanglement and cross-domain image-to-image translation tasks.