 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
Paper and Code



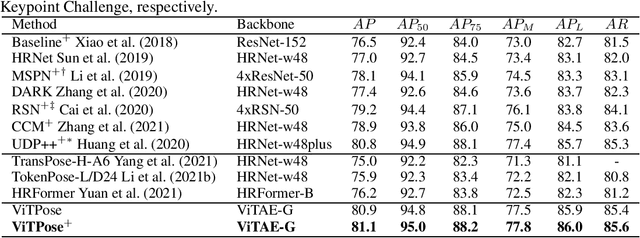
Recently, customized vision transformers have been adapted for human pose estimation and have achieved superior performance with elaborate structures. However, it is still unclear whether plain vision transformers can facilitate pose estimation. In this paper, we take the first step toward answering the question by employing a plain and non-hierarchical vision transformer together with simple deconvolution decoders termed ViTPose for human pose estimation. We demonstrate that a plain vision transformer with MAE pretraining can obtain superior performance after finetuning on human pose estimation datasets. ViTPose has good scalability with respect to model size and flexibility regarding input resolution and token number. Moreover, it can be easily pretrained using the unlabeled pose data without the need for large-scale upstream ImageNet data. Our biggest ViTPose model based on the ViTAE-G backbone with 1 billion parameters obtains the best 80.9 mAP on the MS COCO test-dev set, while the ensemble models further set a new state-of-the-art for human pose estimation, i.e., 81.1 mAP. The source code and models will be released at https://github.com/ViTAE-Transformer/ViTPose.