 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSA: Learning Varied-Size Window Attention in Vision Transformers
Paper and Code
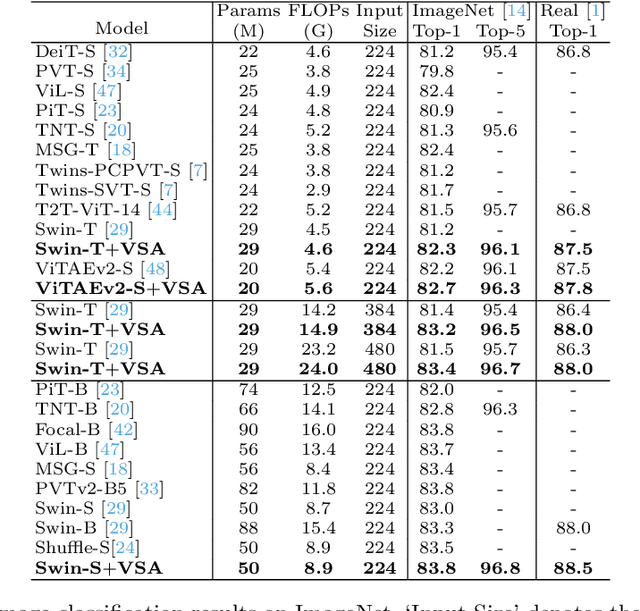
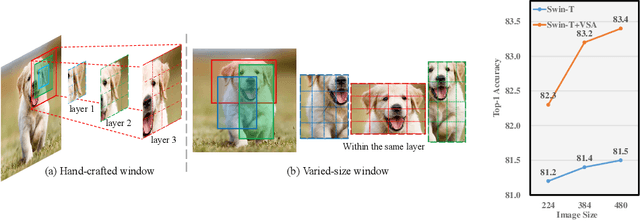
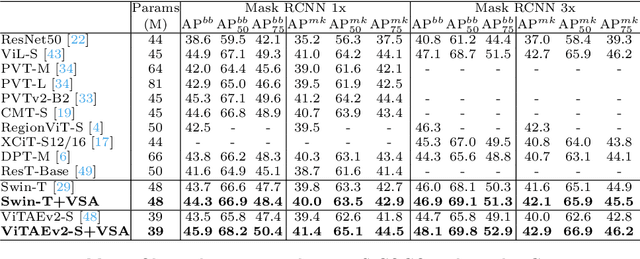
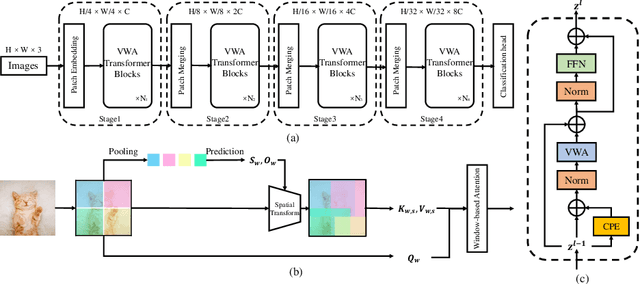
Attention within windows has been widely explored in vision transformers to balance the performance, computation complexity, and memory footprint. However, current models adopt a hand-crafted fixed-size window design, which restricts their capacity of modeling long-term dependencies and adapting to objects of different sizes. To address this drawback, we propose \textbf{V}aried-\textbf{S}ize Window \textbf{A}ttention (VSA) to learn adaptive window configurations from data. Specifically, based on the tokens within each default window, VSA employs a window regression module to predict the size and location of the target window, i.e., the attention area where the key and value tokens are sampled. By adopting VSA independently for each attention head, it can model long-term dependencies, capture rich context from diverse windows, and promote information exchange among overlapped windows. VSA is an easy-to-implement module that can replace the window attention in state-of-the-art representative models with minor modifications and negligible extra computational cost while improving their performance by a large margin, e.g., 1.1\% for Swin-T on ImageNet classification. In addition, the performance gain increases when using larger images for training and test. Experimental results on more downstream tasks, including object detection, instance segmentation, and semantic segmentation, further demonstrate the superiority of VSA over the vanilla window attention in dealing with objects of different sizes. The code will be released https://github.com/ViTAE-Transformer/ViTAE-VSA.