 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Tuning by Manipulating Hidden States of Pretrained Language Models For Classification Tasks
Paper and Code
Apr 13, 2022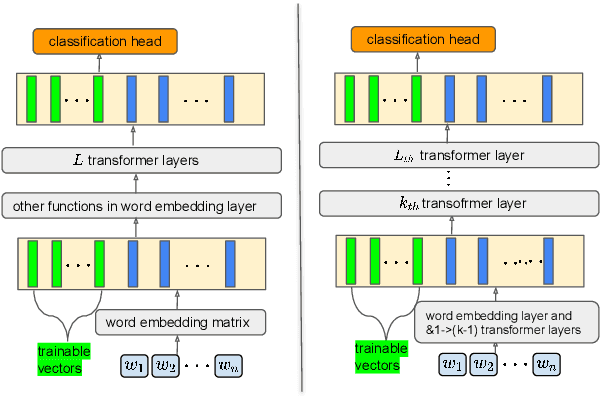
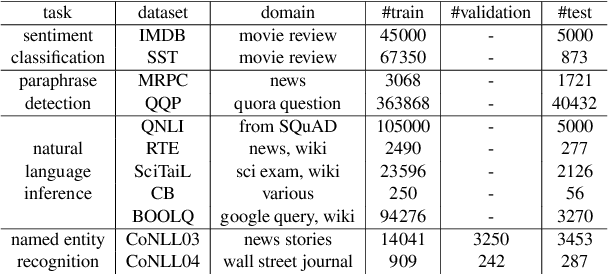
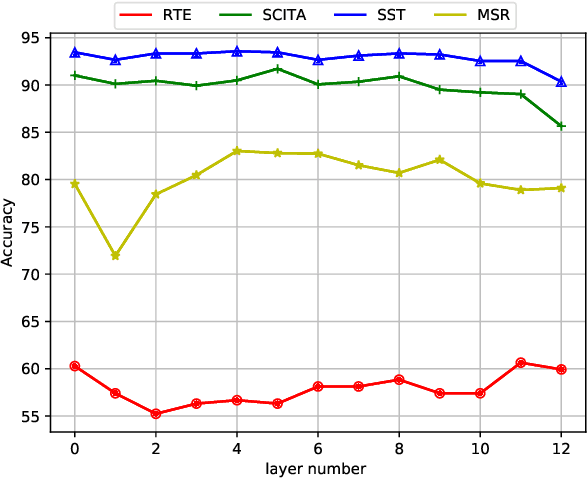
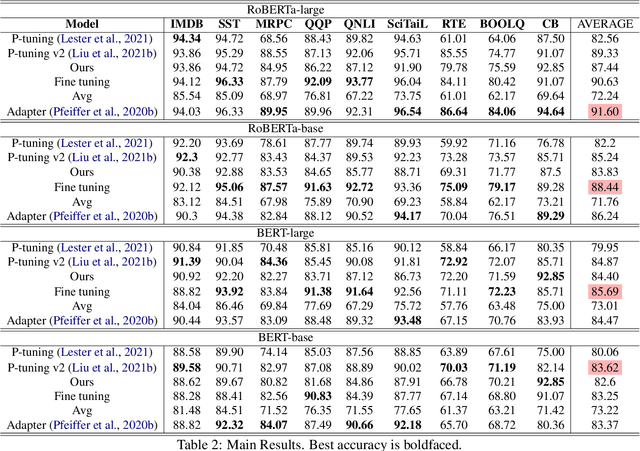
Parameter-efficient tuning aims to distill knowledge for downstream tasks by optimizing a few introduced parameters while freezing the pretrained language models (PLMs). Continuous prompt tuning which prepends a few trainable vectors to the embeddings of input is one of these methods and has drawn much attention due to its effectiveness and efficiency. This family of methods can be illustrated as exerting nonlinear transformations of hidden states inside PLMs. However, a natural question is ignored: can the hidden states be directly used for classification without changing them? In this paper, we aim to answer this question by proposing a simple tuning method which only introduces three trainable vectors. Firstly, we integrate all layers hidden states using the introduced vectors. And then, we input the integrated hidden state(s) to a task-specific linear classifier to predict categories. This scheme is similar to the way ELMo utilises hidden states except that they feed the hidden states to LSTM-based models. Although our proposed tuning scheme is simple, it achieves comparable performance with prompt tuning methods like P-tuning and P-tuning v2, verifying that original hidden states do contain useful information for classification tasks. Moreover, our method has an advantage over prompt tuning in terms of time and the number of parameters.