 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMOS: The Samsung Open MOS Dataset for the Evaluation of Neural Text-to-Speech Synthesis
Paper and Code
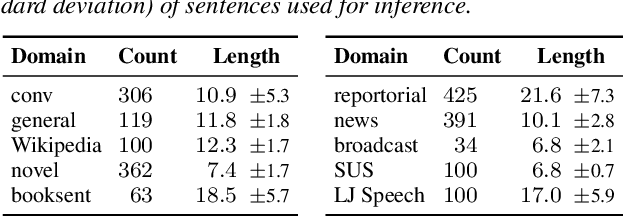
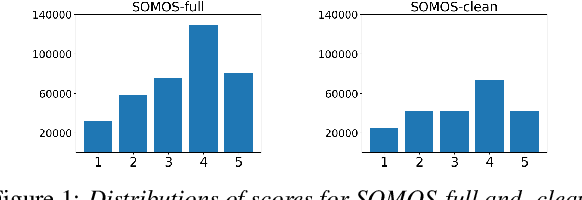
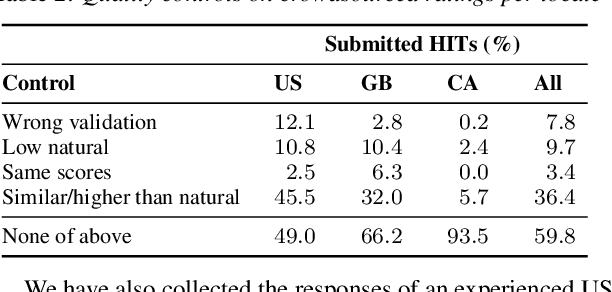
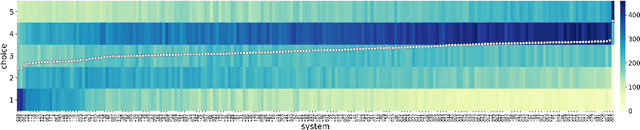
In this work, we present the SOMOS dataset, the first large-scale mean opinion scores (MOS) dataset consisting of solely neural text-to-speech (TTS) samples. It can be employed to train automatic MOS prediction systems focused on the assessment of modern synthesizers, and can stimulate advancements in acoustic model evaluation. It consists of 20K synthetic utterances of the LJ Speech voice, a public domain speech dataset which is a common benchmark for building neural acoustic models and vocoders. Utterances are generated from 200 TTS systems including vanilla neural acoustic models as well as models which allow prosodic variations. An LPCNet vocoder is used for all systems, so that the samples' variation depends only on the acoustic models. The synthesized utterances provide balanced and adequate domain and length coverage. We collect MOS naturalness evaluations on 3 English Amazon Mechanical Turk locales and share practices leading to reliable crowdsourced annotations for this task. Baseline results of state-of-the-art MOS prediction models on the SOMOS dataset are presented, while we show the challenges that such models face when assigned to evaluate synthetic utterances.