 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual multi-channel speech separation, dereverberation and recognition
Paper and Code
Apr 08, 2022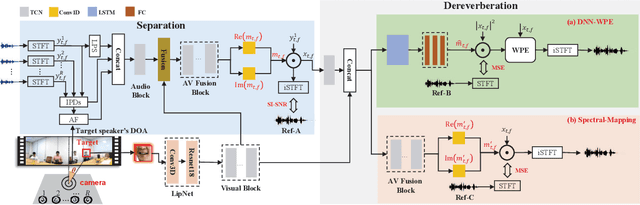

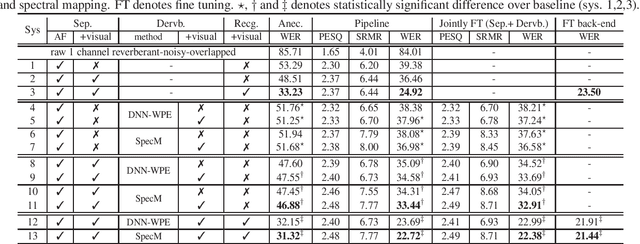
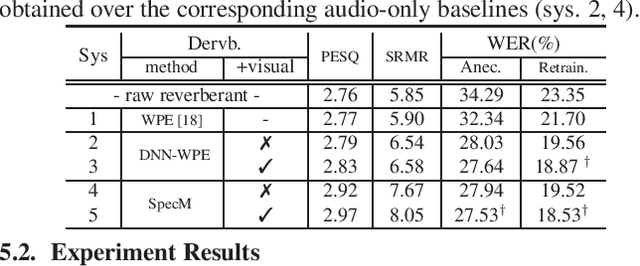
Despite the rapid advance of automatic speech recognition (ASR) technologies, accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, audio-visual speech enhancement techniques have been developed, although predominantly targeting overlapping speech separation and recognition tasks. In this paper, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all three stages of the system is proposed. The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively. The learning cost function mismatch between the separation and dereverberation models and their integration with the back-end recognition system is minimised using fine-tuning on the MSE and LF-MMI criteria. Experiments conducted on the LRS2 dataset suggest that the proposed audio-visual multi-channel speech separation, dereverberation and recognition system outperforms the baseline audio-visual multi-channel speech separation and recognition system containing no dereverberation module by a statistically significant word error rate (WER) reduction of 2.06% absolute (8.77% relative).