 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLDC: Hindi Legal Documents Corpus
Paper and Code


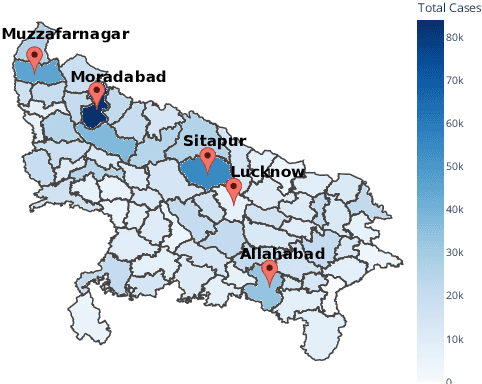
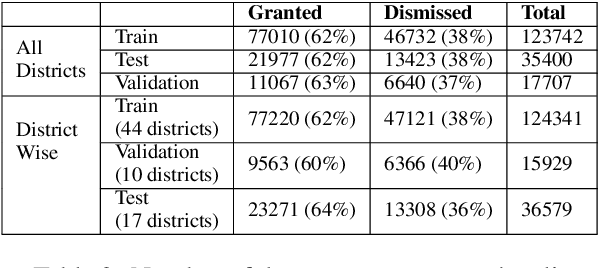
Many populous countries including India are burdened with a considerable backlog of legal cases. Development of automated systems that could process legal documents and augment legal practitioners can mitigate this. However, there is a dearth of high-quality corpora that is needed to develop such data-driven systems. The problem gets even more pronounced in the case of low resource languages such as Hindi. In this resource paper, we introduce the Hindi Legal Documents Corpus (HLDC), a corpus of more than 900K legal documents in Hindi. Documents are cleaned and structured to enable the development of downstream applications. Further, as a use-case for the corpus, we introduce the task of bail prediction. We experiment with a battery of models and propose a Multi-Task Learning (MTL) based model for the same. MTL models use summarization as an auxiliary task along with bail prediction as the main task. Experiments with different models are indicative of the need for further research in this area. We release the corpus and model implementation code with this paper: https://github.com/Exploration-Lab/HLDC