 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Collide: Recommendation System Model Compression with Learned Hash Functions
Paper and Code
Mar 28, 2022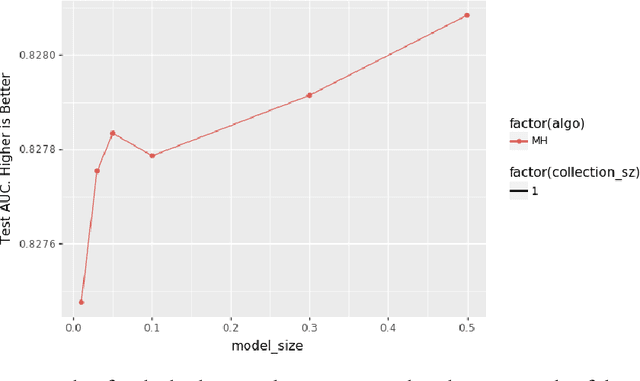

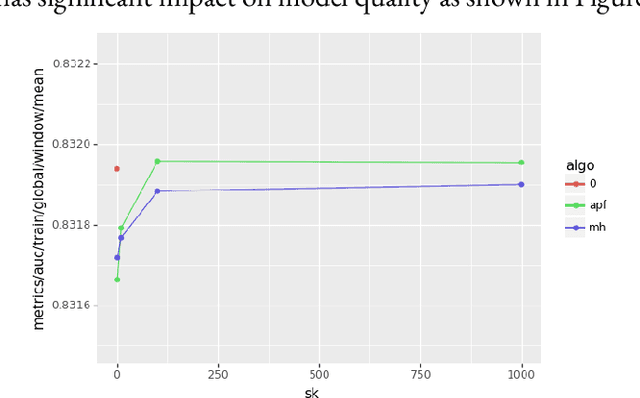
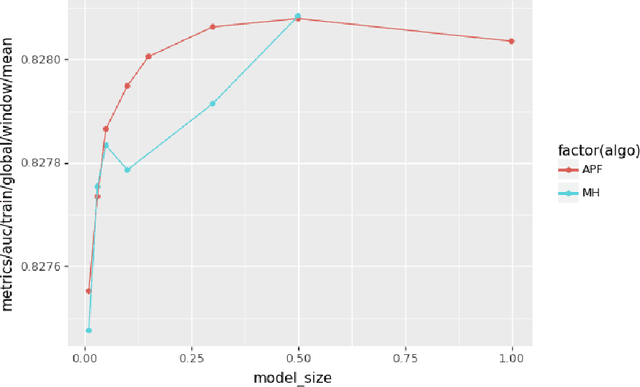
A key characteristic of deep recommendation models is the immense memory requirements of their embedding tables. These embedding tables can often reach hundreds of gigabytes which increases hardware requirements and training cost. A common technique to reduce model size is to hash all of the categorical variable identifiers (ids) into a smaller space. This hashing reduces the number of unique representations that must be stored in the embedding table; thus decreasing its size. However, this approach introduces collisions between semantically dissimilar ids that degrade model quality. We introduce an alternative approach, Learned Hash Functions, which instead learns a new mapping function that encourages collisions between semantically similar ids. We derive this learned mapping from historical data and embedding access patterns. We experiment with this technique on a production model and find that a mapping informed by the combination of access frequency and a learned low dimension embedding is the most effective. We demonstrate a small improvement relative to the hashing trick and other collision related compression techniques. This is ongoing work that explores the impact of categorical id collisions on recommendation model quality and how those collisions may be controlled to improve model performance.