 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Discrimination for Self-Supervised Learning on Point Clouds
Paper and Code
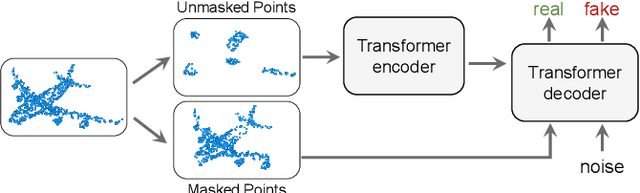
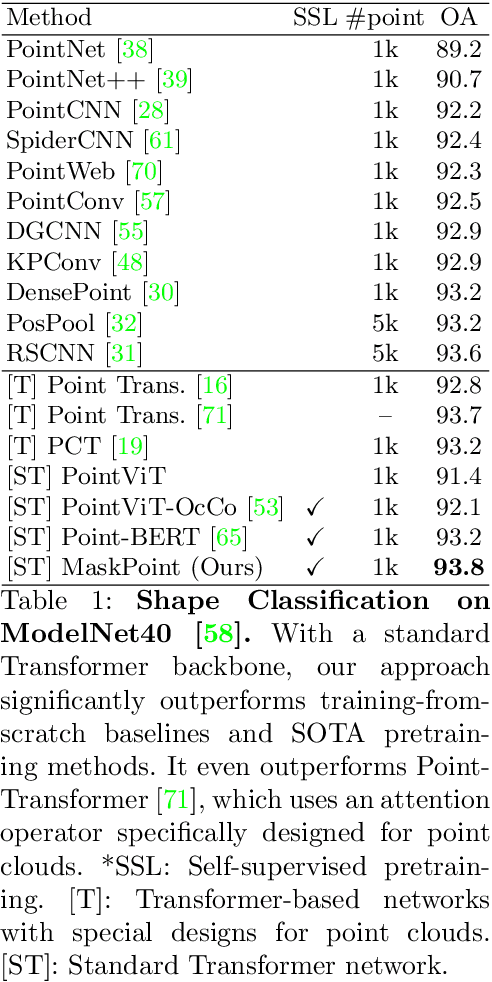
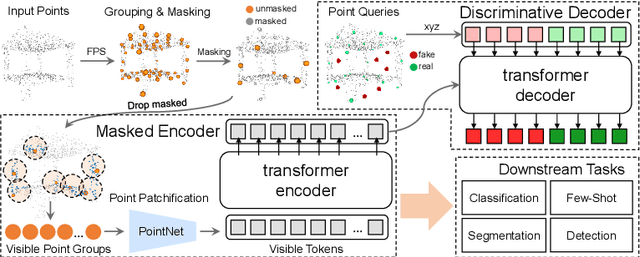

Masked autoencoding has achieved great success for self-supervised learning in the image and language domains. However, mask based pretraining has yet to show benefits for point cloud understanding, likely due to standard backbones like PointNet being unable to properly handle the training versus testing distribution mismatch introduced by masking during training. In this paper, we bridge this gap by proposing a discriminative mask pretraining Transformer framework, MaskPoint}, for point clouds. Our key idea is to represent the point cloud as discrete occupancy values (1 if part of the point cloud; 0 if not), and perform simple binary classification between masked object points and sampled noise points as the proxy task. In this way, our approach is robust to the point sampling variance in point clouds, and facilitates learning rich representations. We evaluate our pretrained models across several downstream tasks, including 3D shape classification, segmentation, and real-word object detection, and demonstrate state-of-the-art results while achieving a significant pretraining speedup (e.g., 4.1x on ScanNet) compared to the prior state-of-the-art Transformer baseline. Code will be publicly available at https://github.com/haotian-liu/MaskPoint.