 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Markov Games with Adversarial Opponents: Efficient Algorithms and Fundamental Limits
Paper and Code
Mar 14, 2022
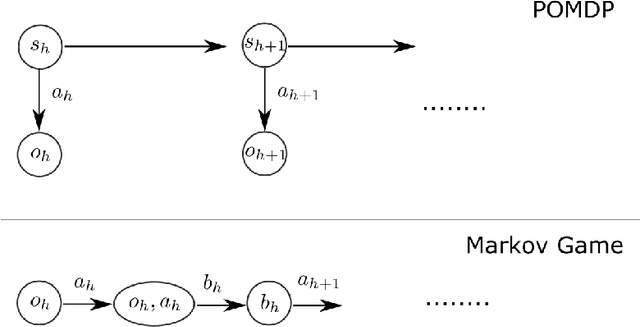
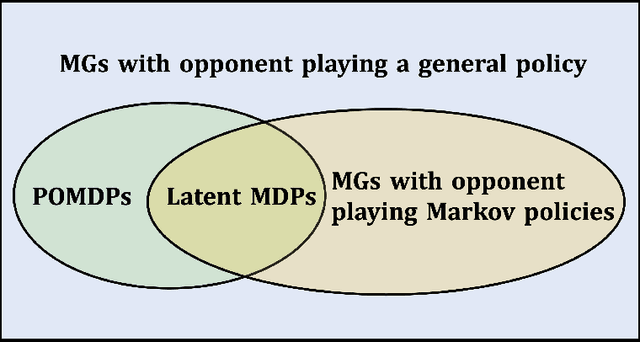
An ideal strategy in zero-sum games should not only grant the player an average reward no less than the value of Nash equilibrium, but also exploit the (adaptive) opponents when they are suboptimal. While most existing works in Markov games focus exclusively on the former objective, it remains open whether we can achieve both objectives simultaneously. To address this problem, this work studies no-regret learning in Markov games with adversarial opponents when competing against the best fixed policy in hindsight. Along this direction, we present a new complete set of positive and negative results: When the policies of the opponents are revealed at the end of each episode, we propose new efficient algorithms achieving $\sqrt{K}$-regret bounds when either (1) the baseline policy class is small or (2) the opponent's policy class is small. This is complemented with an exponential lower bound when neither conditions are true. When the policies of the opponents are not revealed, we prove a statistical hardness result even in the most favorable scenario when both above conditions are true. Our hardness result is much stronger than the existing hardness results which either only involve computational hardness, or require further restrictions on the algorithms.