 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN Training Acceleration via Exploring GPGPU Friendly Sparsity
Paper and Code
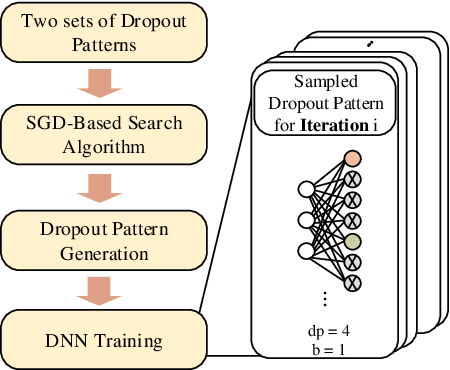
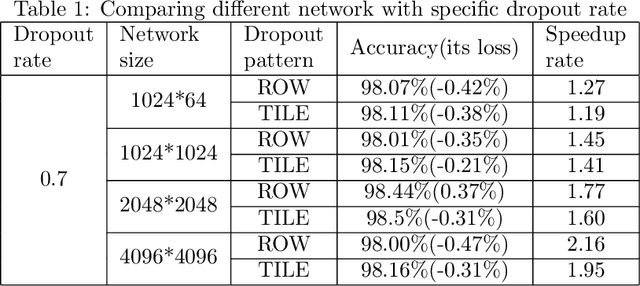
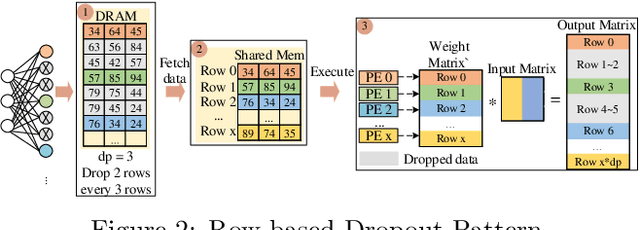
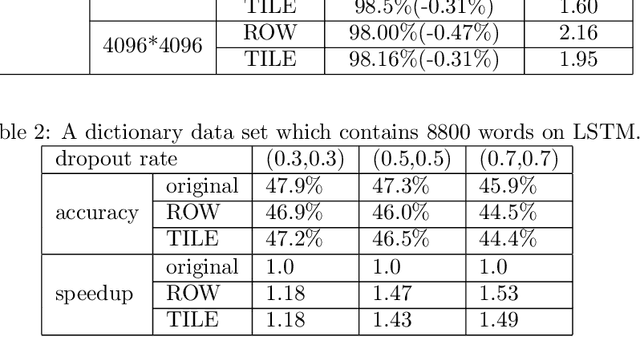
The training phases of Deep neural network~(DNN) consumes enormous processing time and energy. Compression techniques utilizing the sparsity of DNNs can effectively accelerate the inference phase of DNNs. However, it is hardly used in the training phase because the training phase involves dense matrix-multiplication using General-Purpose Computation on Graphics Processors (GPGPU), which endorse the regular and structural data layout. In this paper, we first propose the Approximate Random Dropout that replaces the conventional random dropout of neurons and synapses with a regular and online generated row-based or tile-based dropout patterns to eliminate the unnecessary computation and data access for the multilayer perceptron~(MLP) and long short-term memory~(LSTM). We then develop a SGD-based Search Algorithm that produces the distribution of row-based or tile-based dropout patterns to compensate for the potential accuracy loss. Moreover, aiming at the convolution neural network~(CNN) training acceleration, we first explore the importance and sensitivity of input feature maps; and then propose the sensitivity-aware dropout method to dynamically drop the input feature maps based on their sensitivity so as to achieve greater forward and backward training acceleration while reserving better NN accuracy. To facilitate DNN programming, we build a DNN training computation framework that unifies the proposed techniques in the software stack. As a result, the GPGPU only needs to support the basic operator -- matrix multiplication and can achieve significant performance improvement regardless of DNN model.