 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond
Paper and Code
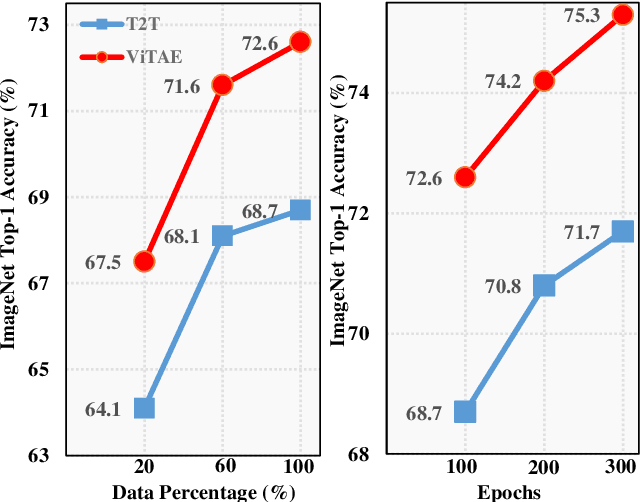
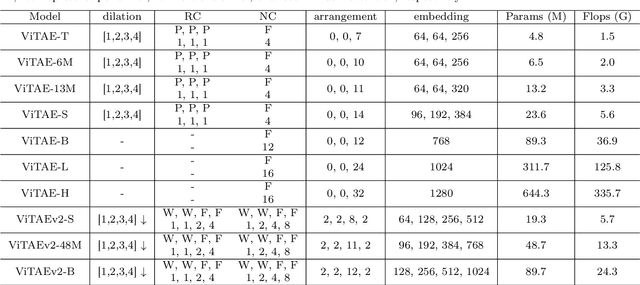
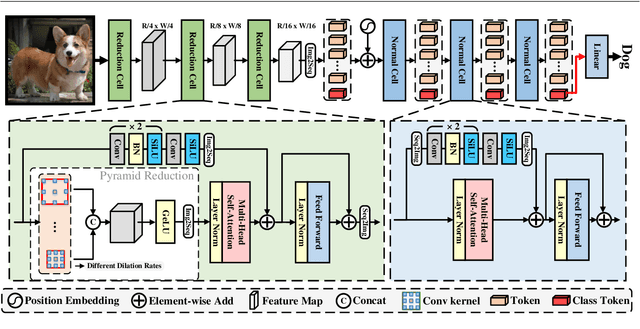
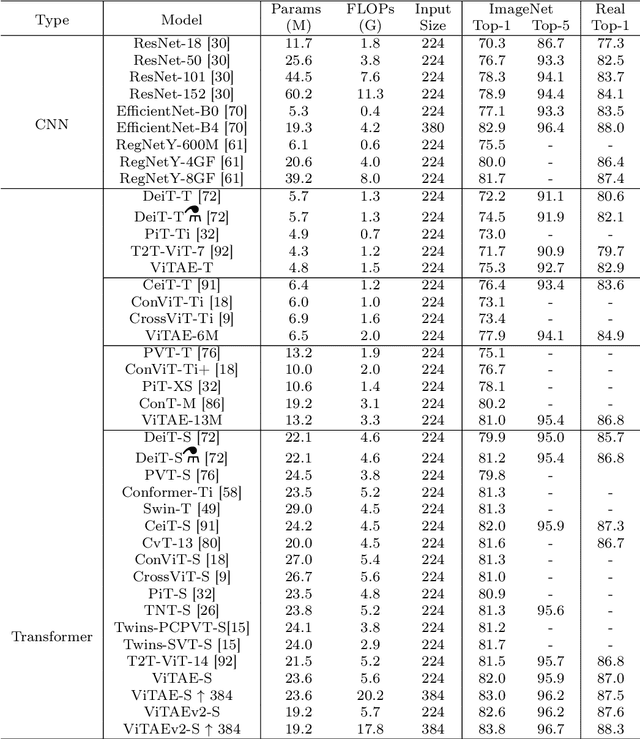
Vision transformers have shown great potential in various computer vision tasks owing to their strong capability to model long-range dependency using the self-attention mechanism. Nevertheless, they treat an image as a 1D sequence of visual tokens, lacking an intrinsic inductive bias (IB) in modeling local visual structures and dealing with scale variance, which is instead learned implicitly from large-scale training data with longer training schedules. In this paper, we propose a Vision Transformer Advanced by Exploring intrinsic IB from convolutions, i.e., ViTAE. Technically, ViTAE has several spatial pyramid reduction modules to downsample and embed the input image into tokens with rich multi-scale context using multiple convolutions with different dilation rates. In this way, it acquires an intrinsic scale invariance IB and can learn robust feature representation for objects at various scales. Moreover, in each transformer layer, ViTAE has a convolution block parallel to the multi-head self-attention module, whose features are fused and fed into the feed-forward network. Consequently, it has the intrinsic locality IB and is able to learn local features and global dependencies collaboratively. The proposed two kinds of cells are stacked in both isotropic and multi-stage manners to formulate two families of ViTAE models, i.e., the vanilla ViTAE and ViTAEv2. Experiments on the ImageNet dataset as well as downstream tasks on the MS COCO, ADE20K, and AP10K datasets validate the superiority of our models over the baseline transformer models and concurrent works. Besides, we scale up our ViTAE model to 644M parameters and obtain the state-of-the-art classification performance, i.e., 88.5% Top-1 classification accuracy on ImageNet validation set and the best 91.2% Top-1 accuracy on ImageNet real validation set, without using extra private data.