 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom FreEM to D'AlemBERT: a Large Corpus and a Language Model for Early Modern French
Paper and Code

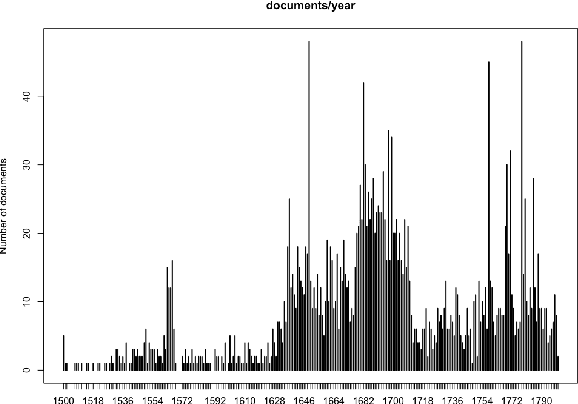
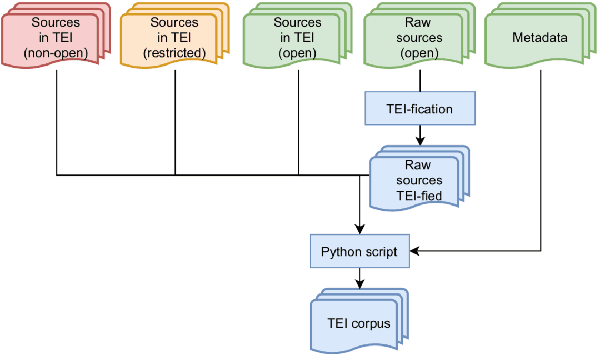
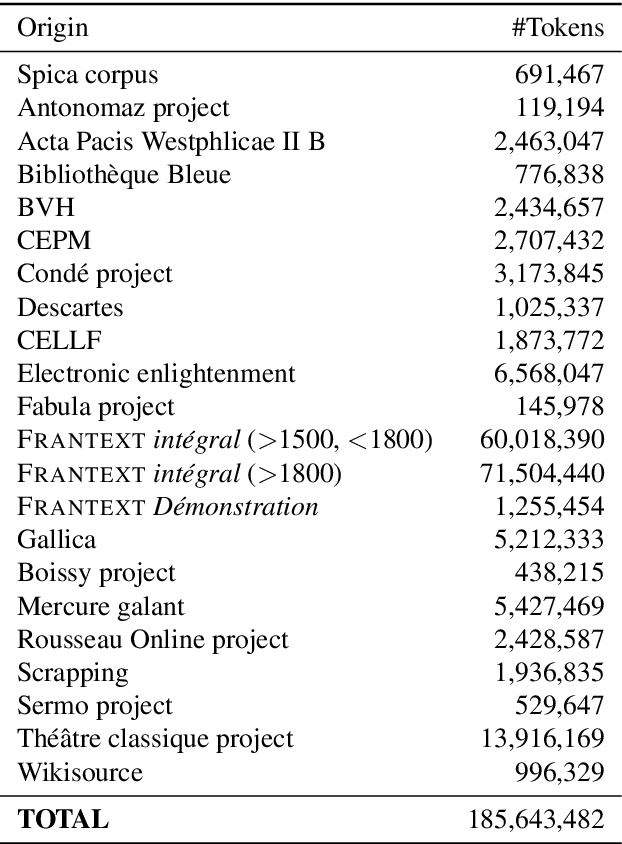
Language models for historical states of language are becoming increasingly important to allow the optimal digitisation and analysis of old textual sources. Because these historical states are at the same time more complex to process and more scarce in the corpora available, specific efforts are necessary to train natural language processing (NLP) tools adapted to the data. In this paper, we present our efforts to develop NLP tools for Early Modern French (historical French from the 16$^\text{th}$ to the 18$^\text{th}$ centuries). We present the $\text{FreEM}_{\text{max}}$ corpus of Early Modern French and D'AlemBERT, a RoBERTa-based language model trained on $\text{FreEM}_{\text{max}}$. We evaluate the usefulness of D'AlemBERT by fine-tuning it on a part-of-speech tagging task, outperforming previous work on the test set. Importantly, we find evidence for the transfer learning capacity of the language model, since its performance on lesser-resourced time periods appears to have been boosted by the more resourced ones. We release D'AlemBERT and the open-sourced subpart of the $\text{FreEM}_{\text{max}}$ corpus.