 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Reinforcement Learning Policies through Counterfactual Trajectories
Paper and Code
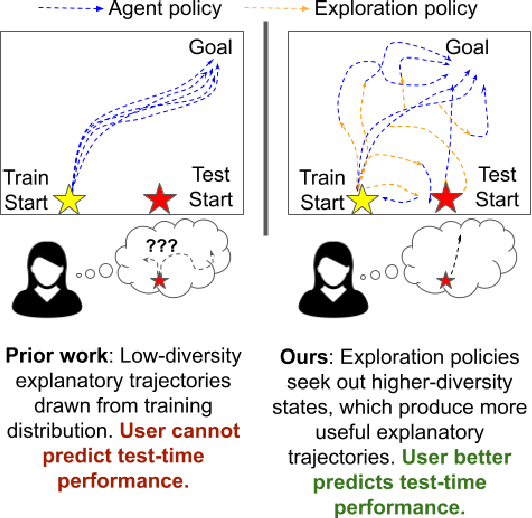
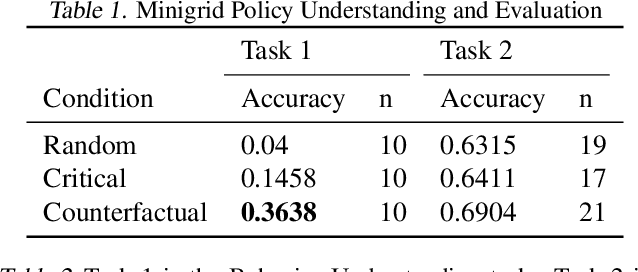
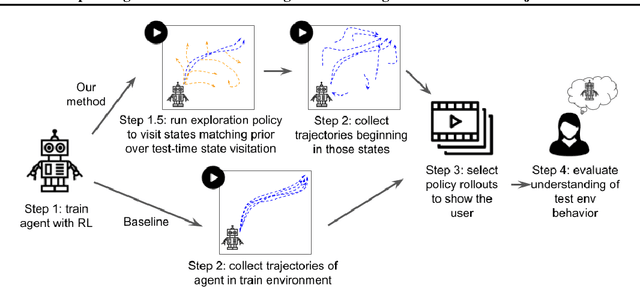
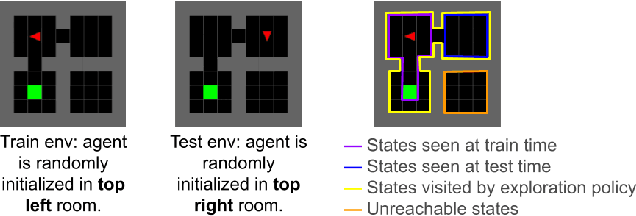
In order for humans to confidently decide where to employ RL agents for real-world tasks, a human developer must validate that the agent will perform well at test-time. Some policy interpretability methods facilitate this by capturing the policy's decision making in a set of agent rollouts. However, even the most informative trajectories of training time behavior may give little insight into the agent's behavior out of distribution. In contrast, our method conveys how the agent performs under distribution shifts by showing the agent's behavior across a wider trajectory distribution. We generate these trajectories by guiding the agent to more diverse unseen states and showing the agent's behavior there. In a user study, we demonstrate that our method enables users to score better than baseline methods on one of two agent validation tasks.