 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHashSet -- A Dataset For Hashtag Segmentation
Paper and Code
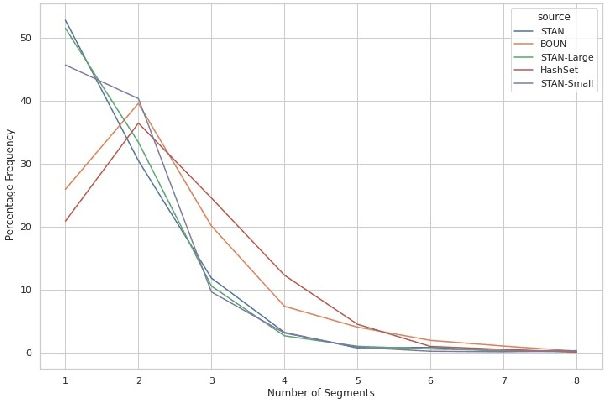
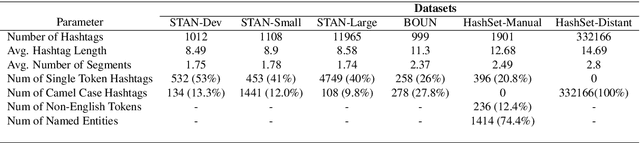
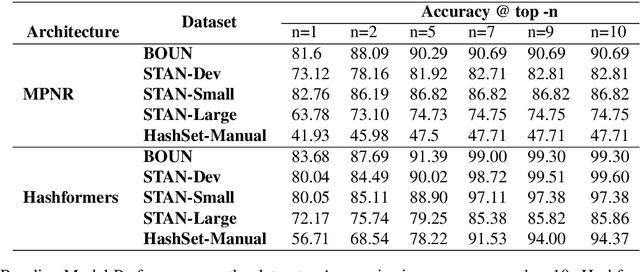

Hashtag segmentation is the task of breaking a hashtag into its constituent tokens. Hashtags often encode the essence of user-generated posts, along with information like topic and sentiment, which are useful in downstream tasks. Hashtags prioritize brevity and are written in unique ways -- transliterating and mixing languages, spelling variations, creative named entities. Benchmark datasets used for the hashtag segmentation task -- STAN, BOUN -- are small in size and extracted from a single set of tweets. However, datasets should reflect the variations in writing styles of hashtags and also account for domain and language specificity, failing which the results will misrepresent model performance. We argue that model performance should be assessed on a wider variety of hashtags, and datasets should be carefully curated. To this end, we propose HashSet, a dataset comprising of: a) 1.9k manually annotated dataset; b) 3.3M loosely supervised dataset. HashSet dataset is sampled from a different set of tweets when compared to existing datasets and provides an alternate distribution of hashtags to build and validate hashtag segmentation models. We show that the performance of SOTA models for Hashtag Segmentation drops substantially on proposed dataset, indicating that the proposed dataset provides an alternate set of hashtags to train and assess models.