 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Denoise Raw Mobile UI Layouts for Improving Datasets at Scale
Paper and Code
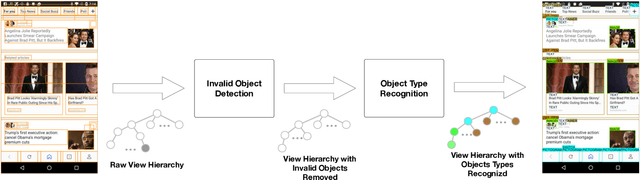
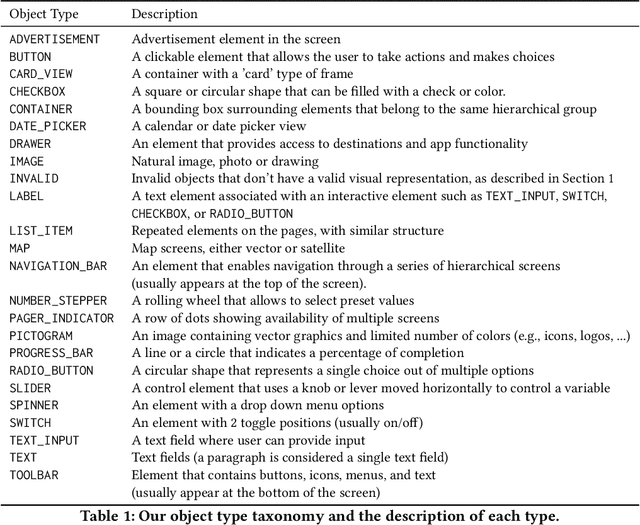
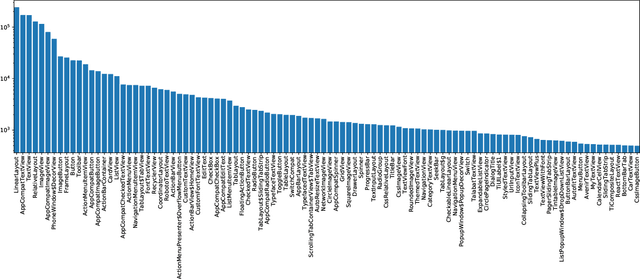
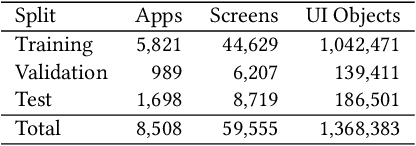
The layout of a mobile screen is a critical data source for UI design research and semantic understanding of the screen. However, UI layouts in existing datasets are often noisy, have mismatches with their visual representation, or consists of generic or app-specific types that are difficult to analyze and model. In this paper, we propose the CLAY pipeline that uses a deep learning approach for denoising UI layouts, allowing us to automatically improve existing mobile UI layout datasets at scale. Our pipeline takes both the screenshot and the raw UI layout, and annotates the raw layout by removing incorrect nodes and assigning a semantically meaningful type to each node. To experiment with our data-cleaning pipeline, we create the CLAY dataset of 59,555 human-annotated screen layouts, based on screenshots and raw layouts from Rico, a public mobile UI corpus. Our deep models achieve high accuracy with F1 scores of 82.7% for detecting layout objects that do not have a valid visual representation and 85.9% for recognizing object types, which significantly outperforms a heuristic baseline. Our work lays a foundation for creating large-scale high quality UI layout datasets for data-driven mobile UI research and reduces the need of manual labeling efforts that are prohibitively expensive.