 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Combinatorial Optimization Model Using Learning-to-Rank Distillation
Paper and Code
Dec 24, 2021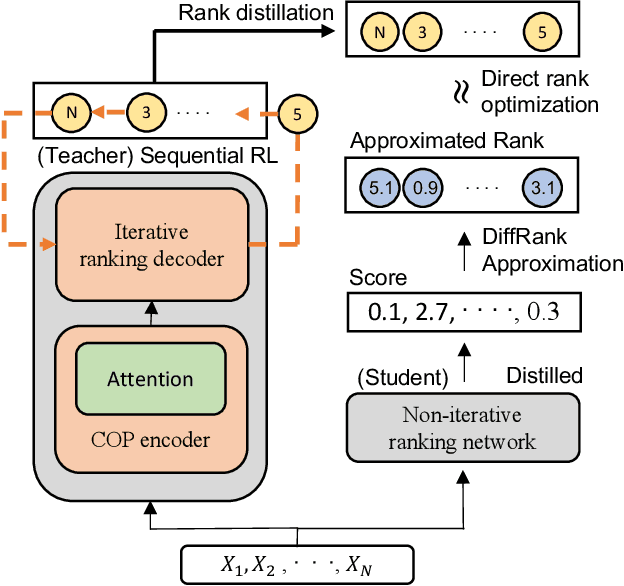
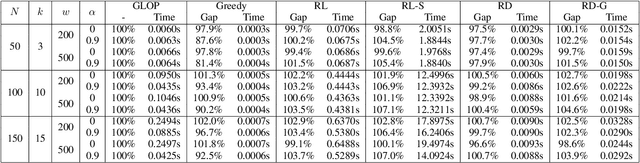
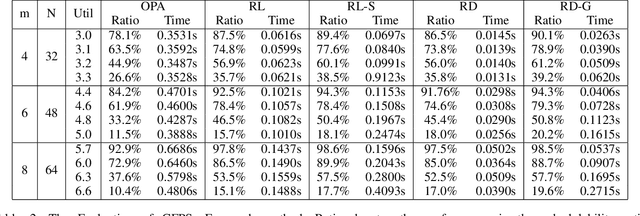
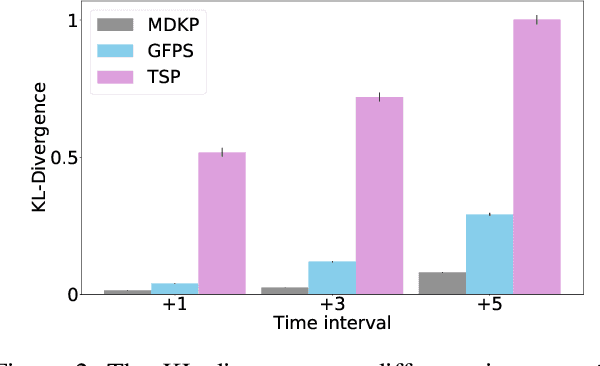
Recently, deep reinforcement learning (RL) has proven its feasibility in solving combinatorial optimization problems (COPs). The learning-to-rank techniques have been studied in the field of information retrieval. While several COPs can be formulated as the prioritization of input items, as is common in the information retrieval, it has not been fully explored how the learning-to-rank techniques can be incorporated into deep RL for COPs. In this paper, we present the learning-to-rank distillation-based COP framework, where a high-performance ranking policy obtained by RL for a COP can be distilled into a non-iterative, simple model, thereby achieving a low-latency COP solver. Specifically, we employ the approximated ranking distillation to render a score-based ranking model learnable via gradient descent. Furthermore, we use the efficient sequence sampling to improve the inference performance with a limited delay. With the framework, we demonstrate that a distilled model not only achieves comparable performance to its respective, high-performance RL, but also provides several times faster inferences. We evaluate the framework with several COPs such as priority-based task scheduling and multidimensional knapsack, demonstrating the benefits of the framework in terms of inference latency and performance.