 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond Corners: Contrastive Learning of Visual Representations for Keypoint Detection and Description Extraction
Paper and Code
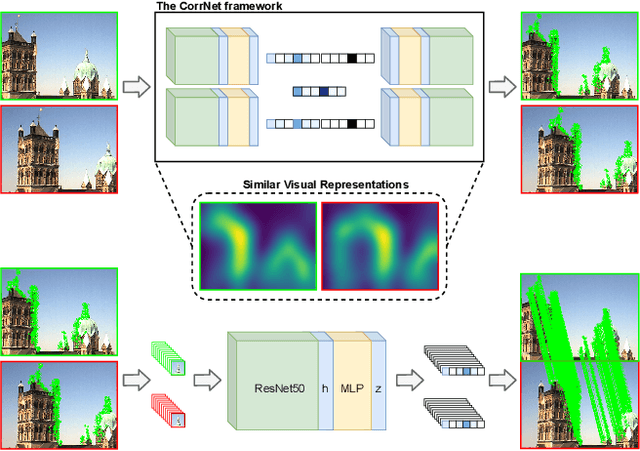
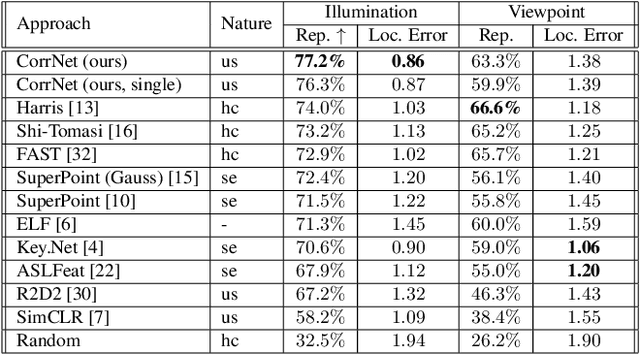
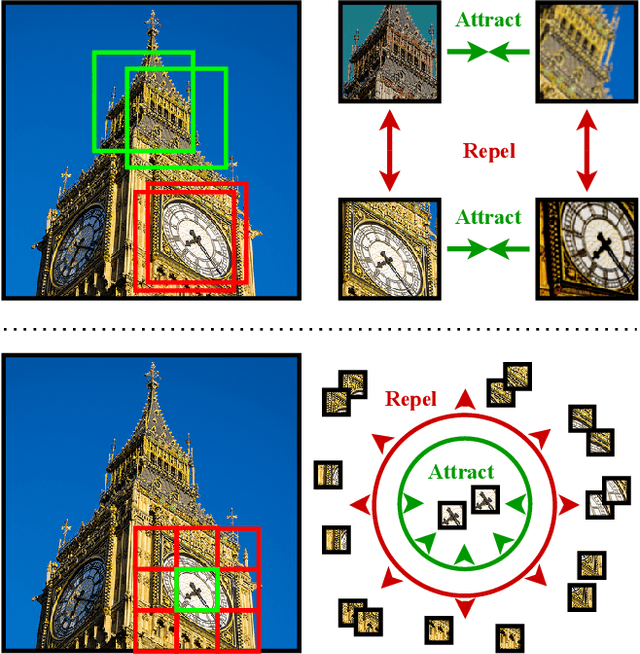
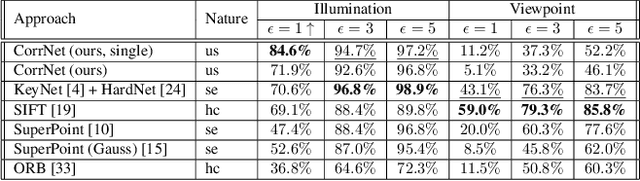
Learnable keypoint detectors and descriptors are beginning to outperform classical hand-crafted feature extraction methods. Recent studies on self-supervised learning of visual representations have driven the increasing performance of learnable models based on deep networks. By leveraging traditional data augmentations and homography transformations, these networks learn to detect corners under adverse conditions such as extreme illumination changes. However, their generalization capabilities are limited to corner-like features detected a priori by classical methods or synthetically generated data. In this paper, we propose the Correspondence Network (CorrNet) that learns to detect repeatable keypoints and to extract discriminative descriptions via unsupervised contrastive learning under spatial constraints. Our experiments show that CorrNet is not only able to detect low-level features such as corners, but also high-level features that represent similar objects present in a pair of input images through our proposed joint guided backpropagation of their latent space. Our approach obtains competitive results under viewpoint changes and achieves state-of-the-art performance under illumination changes.