 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckDST: Measuring Real-World Generalization of Dialogue State Tracking Performance
Paper and Code
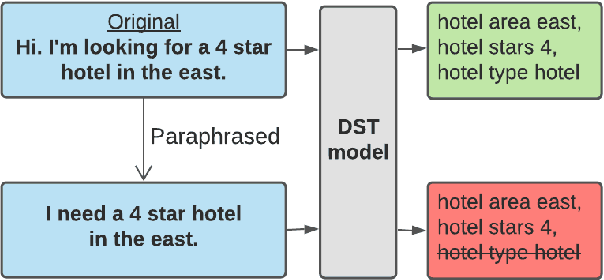
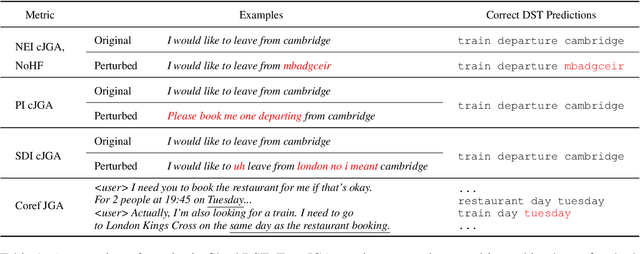
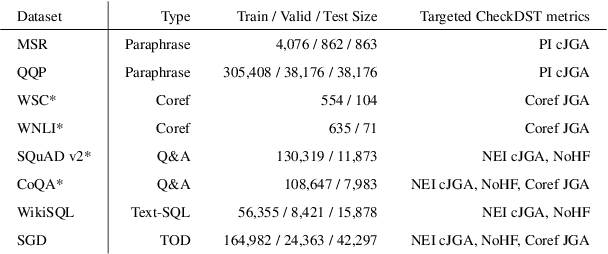
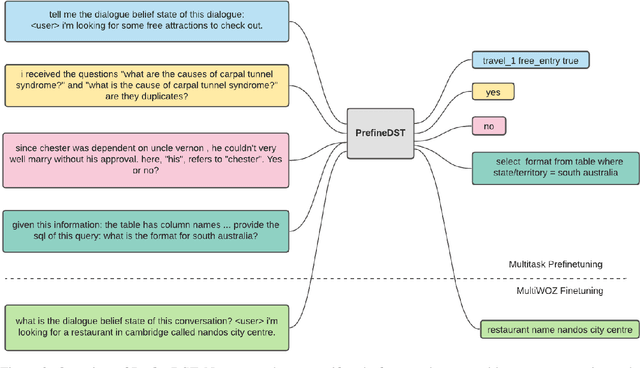
Recent neural models that extend the pretrain-then-finetune paradigm continue to achieve new state-of-the-art results on joint goal accuracy (JGA) for dialogue state tracking (DST) benchmarks. However, we call into question their robustness as they show sharp drops in JGA for conversations containing utterances or dialog flows with realistic perturbations. Inspired by CheckList (Ribeiro et al., 2020), we design a collection of metrics called CheckDST that facilitate comparisons of DST models on comprehensive dimensions of robustness by testing well-known weaknesses with augmented test sets. We evaluate recent DST models with CheckDST and argue that models should be assessed more holistically rather than pursuing state-of-the-art on JGA since a higher JGA does not guarantee better overall robustness. We find that span-based classification models are resilient to unseen named entities but not robust to language variety, whereas those based on autoregressive language models generalize better to language variety but tend to memorize named entities and often hallucinate. Due to their respective weaknesses, neither approach is yet suitable for real-world deployment. We believe CheckDST is a useful guide for future research to develop task-oriented dialogue models that embody the strengths of various methods.