 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary Detection
Paper and Code
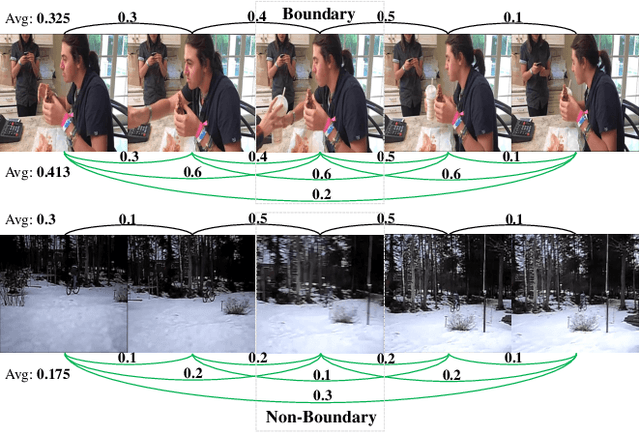
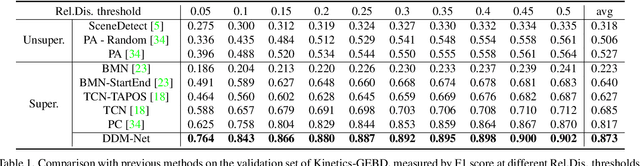
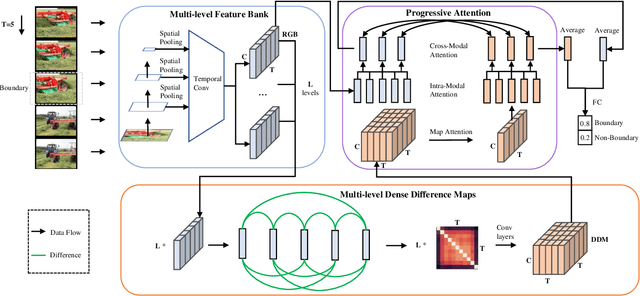
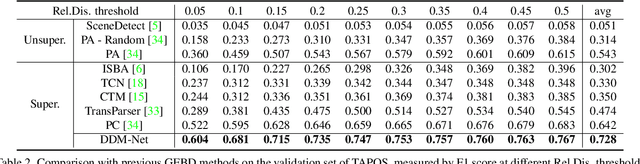
Generic event boundary detection is an important yet challenging task in video understanding, which aims at detecting the moments where humans naturally perceive event boundaries. The main challenge of this task is perceiving various temporal variations of diverse event boundaries. To this end, this paper presents an effective and end-to-end learnable framework (DDM-Net). To tackle the diversity and complicated semantics of event boundaries, we make three notable improvements. First, we construct a feature bank to store multi-level features of space and time, prepared for difference calculation at multiple scales. Second, to alleviate inadequate temporal modeling of previous methods, we present dense difference maps (DDM) to comprehensively characterize the motion pattern. Finally, we exploit progressive attention on multi-level DDM to jointly aggregate appearance and motion clues. As a result, DDM-Net respectively achieves a significant boost of 14% and 8% on Kinetics-GEBD and TAPOS benchmark, and outperforms the top-1 winner solution of LOVEU Challenge@CVPR 2021 without bells and whistles. The state-of-the-art result demonstrates the effectiveness of richer motion representation and more sophisticated aggregation, in handling the diversity of generic event boundary detection. Our codes will be made available soon.