 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Prototype Topic Model with Discriminative Seed Words: Modifying the Category Prior by Self-exploring Supervised Signals
Paper and Code
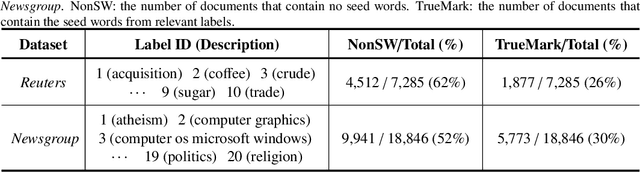
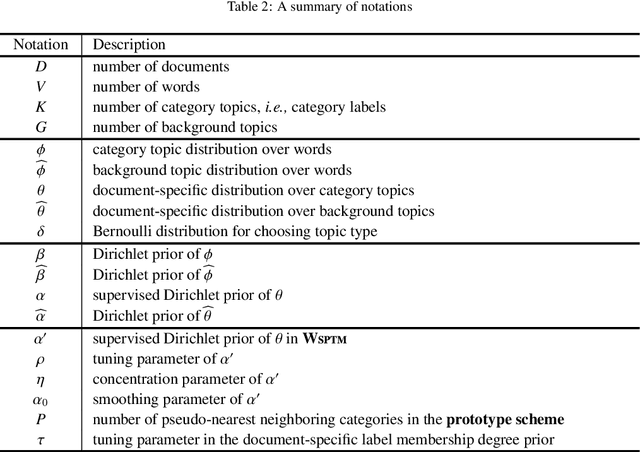
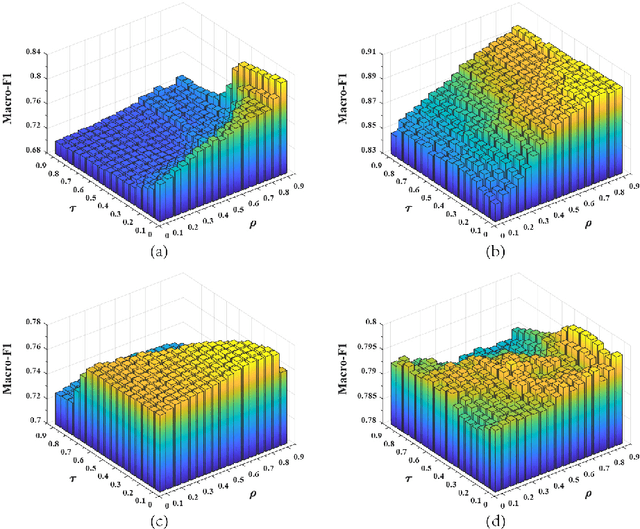
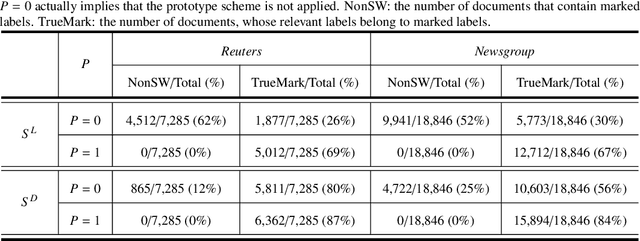
Dataless text classification, i.e., a new paradigm of weakly supervised learning, refers to the task of learning with unlabeled documents and a few predefined representative words of categories, known as seed words. The recent generative dataless methods construct document-specific category priors by using seed word occurrences only, however, such category priors often contain very limited and even noisy supervised signals. To remedy this problem, in this paper we propose a novel formulation of category prior. First, for each document, we consider its label membership degree by not only counting seed word occurrences, but also using a novel prototype scheme, which captures pseudo-nearest neighboring categories. Second, for each label, we consider its frequency prior knowledge of the corpus, which is also a discriminative knowledge for classification. By incorporating the proposed category prior into the previous generative dataless method, we suggest a novel generative dataless method, namely Weakly Supervised Prototype Topic Model (WSPTM). The experimental results on real-world datasets demonstrate that WSPTM outperforms the existing baseline methods.