 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDonut: Document Understanding Transformer without OCR
Paper and Code
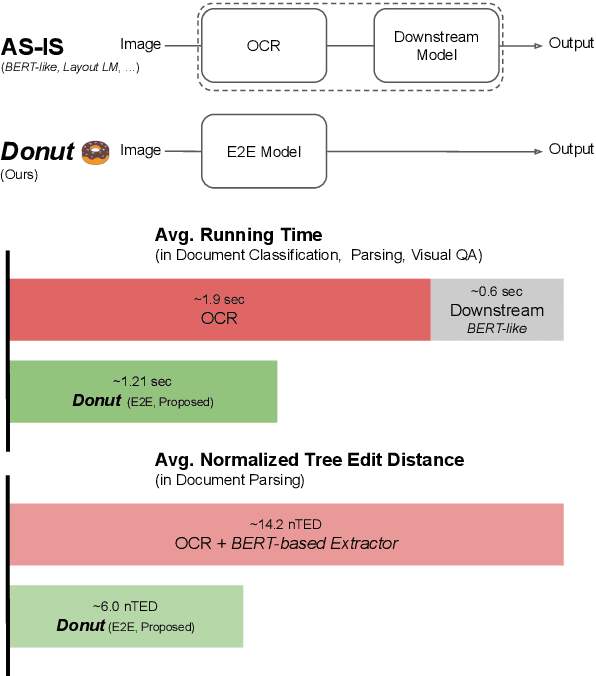
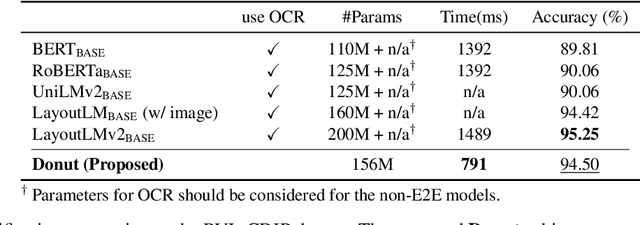
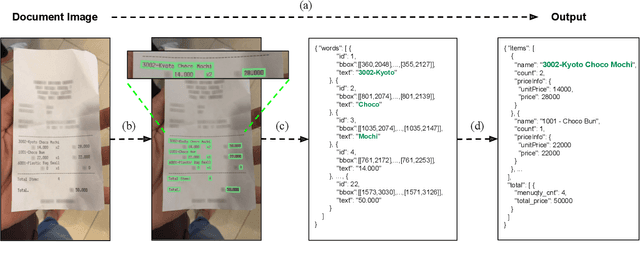

Understanding document images (e.g., invoices) has been an important research topic and has many applications in document processing automation. Through the latest advances in deep learning-based Optical Character Recognition (OCR), current Visual Document Understanding (VDU) systems have come to be designed based on OCR. Although such OCR-based approach promise reasonable performance, they suffer from critical problems induced by the OCR, e.g., (1) expensive computational costs and (2) performance degradation due to the OCR error propagation. In this paper, we propose a novel VDU model that is end-to-end trainable without underpinning OCR framework. To this end, we propose a new task and a synthetic document image generator to pre-train the model to mitigate the dependencies on large-scale real document images. Our approach achieves state-of-the-art performance on various document understanding tasks in public benchmark datasets and private industrial service datasets. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed model especially with consideration for a real-world application.