 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Multi-Flow Network for Video Frame Interpolation
Paper and Code
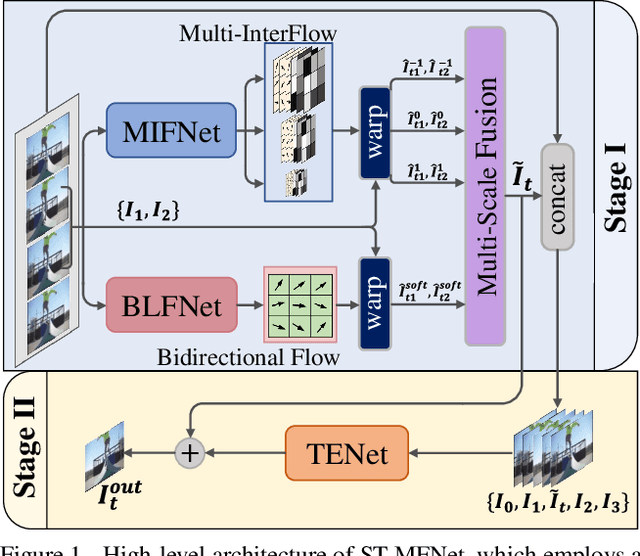
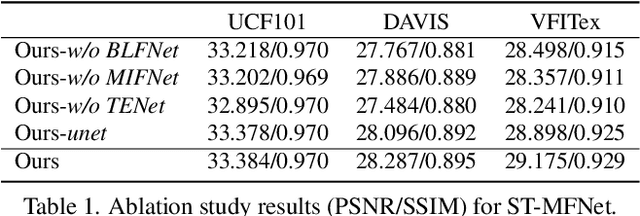
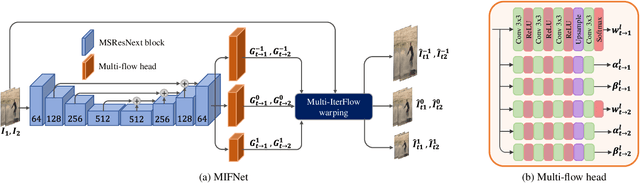
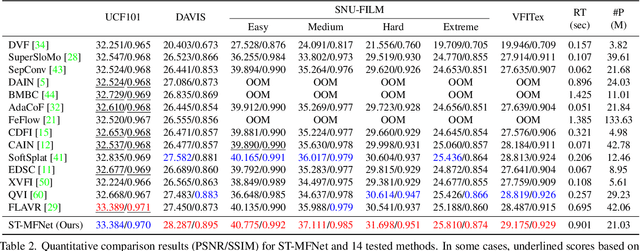
Video frame interpolation (VFI) is currently a very active research topic, with applications spanning computer vision, post production and video encoding. VFI can be extremely challenging, particularly in sequences containing large motions, occlusions or dynamic textures, where existing approaches fail to offer perceptually robust interpolation performance. In this context, we present a novel deep learning based VFI method, ST-MFNet, based on a Spatio-Temporal Multi-Flow architecture. ST-MFNet employs a new multi-scale multi-flow predictor to estimate many-to-one intermediate flows, which are combined with conventional one-to-one optical flows to capture both large and complex motions. In order to enhance interpolation performance for various textures, a 3D CNN is also employed to model the content dynamics over an extended temporal window. Moreover, ST-MFNet has been trained within an ST-GAN framework, which was originally developed for texture synthesis, with the aim of further improving perceptual interpolation quality. Our approach has been comprehensively evaluated -- compared with fourteen state-of-the-art VFI algorithms -- clearly demonstrating that ST-MFNet consistently outperforms these benchmarks on varied and representative test datasets, with significant gains up to 1.09dB in PSNR for cases including large motions and dynamic textures. Project page: https://danielism97.github.io/ST-MFNet.