 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFusion: Visual-LiDAR Fusion with Adaptive Weights for Place Recognition
Paper and Code
Nov 23, 2021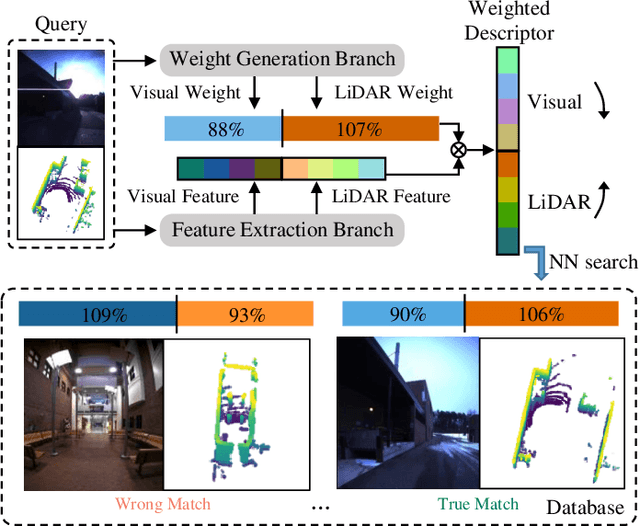
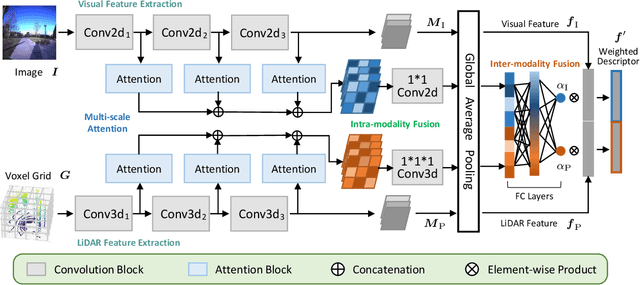
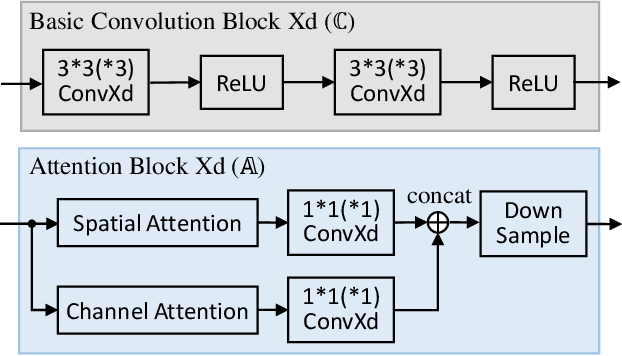

Recent years have witnessed the increasing application of place recognition in various environments, such as city roads, large buildings, and a mix of indoor and outdoor places. This task, however, still remains challenging due to the limitations of different sensors and the changing appearance of environments. Current works only consider the use of individual sensors, or simply combine different sensors, ignoring the fact that the importance of different sensors varies as the environment changes. In this paper, an adaptive weighting visual-LiDAR fusion method, named AdaFusion, is proposed to learn the weights for both images and point cloud features. Features of these two modalities are thus contributed differently according to the current environmental situation. The learning of weights is achieved by the attention branch of the network, which is then fused with the multi-modality feature extraction branch. Furthermore, to better utilize the potential relationship between images and point clouds, we design a twostage fusion approach to combine the 2D and 3D attention. Our work is tested on two public datasets, and experiments show that the adaptive weights help improve recognition accuracy and system robustness to varying environments.