 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Decision Transformer for Offline Hindsight Information Matching
Paper and Code
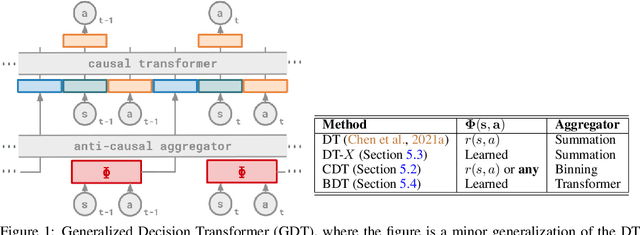
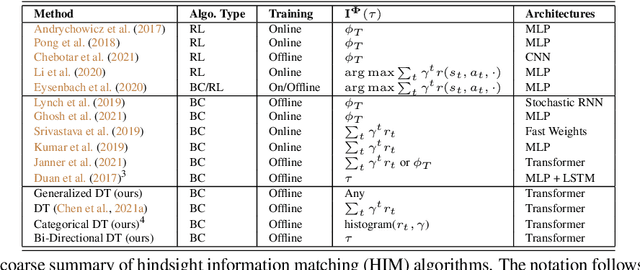

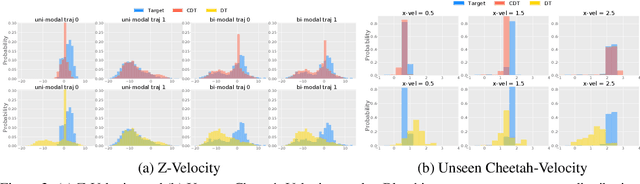
How to extract as much learning signal from each trajectory data has been a key problem in reinforcement learning (RL), where sample inefficiency has posed serious challenges for practical applications. Recent works have shown that using expressive policy function approximators and conditioning on future trajectory information -- such as future states in hindsight experience replay or returns-to-go in Decision Transformer (DT) -- enables efficient learning of multi-task policies, where at times online RL is fully replaced by offline behavioral cloning, e.g. sequence modeling. We demonstrate that all these approaches are doing hindsight information matching (HIM) -- training policies that can output the rest of trajectory that matches some statistics of future state information. We present Generalized Decision Transformer (GDT) for solving any HIM problem, and show how different choices for the feature function and the anti-causal aggregator not only recover DT as a special case, but also lead to novel Categorical DT (CDT) and Bi-directional DT (BDT) for matching different statistics of the future. For evaluating CDT and BDT, we define offline multi-task state-marginal matching (SMM) and imitation learning (IL) as two generic HIM problems, propose a Wasserstein distance loss as a metric for both, and empirically study them on MuJoCo continuous control benchmarks. CDT, which simply replaces anti-causal summation with anti-causal binning in DT, enables the first effective offline multi-task SMM algorithm that generalizes well to unseen and even synthetic multi-modal state-feature distributions. BDT, which uses an anti-causal second transformer as the aggregator, can learn to model any statistics of the future and outperforms DT variants in offline multi-task IL. Our generalized formulations from HIM and GDT greatly expand the role of powerful sequence modeling architectures in modern RL.