 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre we ready for a new paradigm shift? A Survey on Visual Deep MLP
Paper and Code
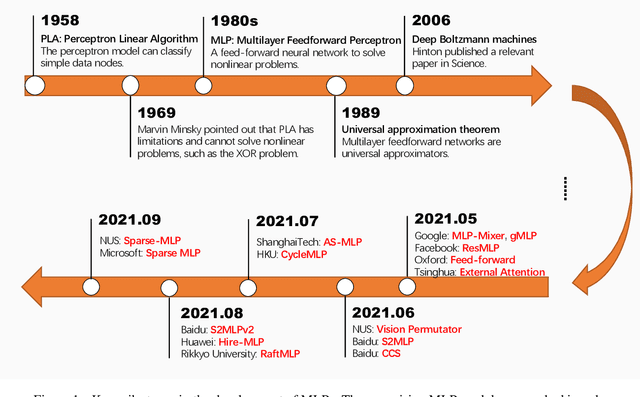

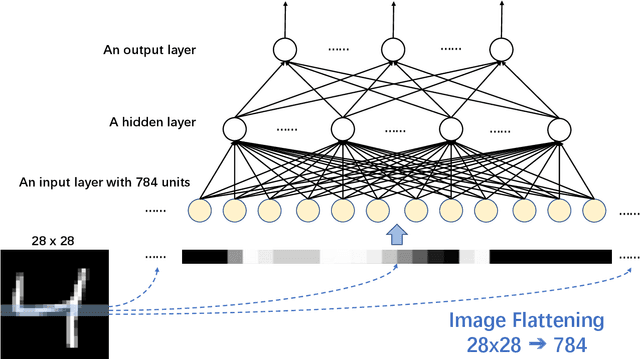
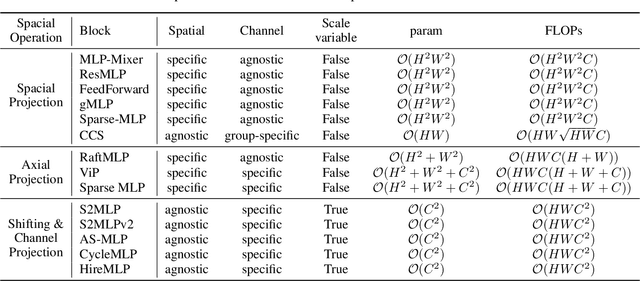
Multilayer perceptron (MLP), as the first neural network structure to appear, was a big hit. But constrained by the hardware computing power and the size of the datasets, it once sank for tens of years. During this period, we have witnessed a paradigm shift from manual feature extraction to the CNN with local receptive field, and further to the Transformer with global receptive field based on self-attention mechanism. And this year (2021), with the introduction of MLP-Mixer, MLP has re-entered the limelight and has attracted extensive research from the computer vision community. Compare to the conventional MLP, it gets deeper but changes the input from full flattening to patch flattening. Given its high performance and less need for vision-specific inductive bias, the community can't help but wonder, \emph{Will deep MLP, the simplest structure with global receptive field but no attention, become a new computer vision paradigm}? To answer this question, this survey aims to provide a comprehensive overview of the recent development of deep MLP models in vision. Specifically, we review these MLPs in detail, from the subtle sub-module design to the global network structure. We compare the receptive field, computational complexity, and other properties of different network designs in order to understand the development path of MLPs clearly. The investigation shows that MLPs' resolution-sensitivity and computational densities remain unresolved, and pure MLPs are gradually evolving towards CNN-like. We suggest that the current data volume and computational power are not ready to embrace pure MLPs, and artificial visual guidance remains important. Finally, we provide our viewpoint about open research directions and potential future works. We hope this effort will ignite further interest in the community and encourage better visual tailored design for the neural network in the future.