Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free Risk-Sensitive Reinforcement Learning
Paper and Code
Nov 04, 2021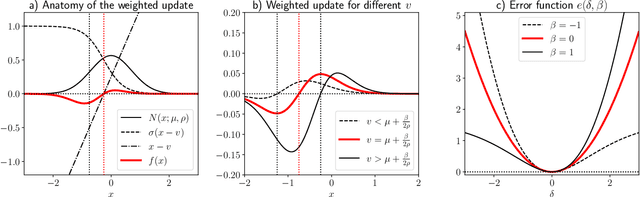
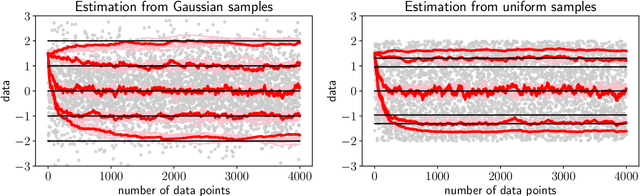
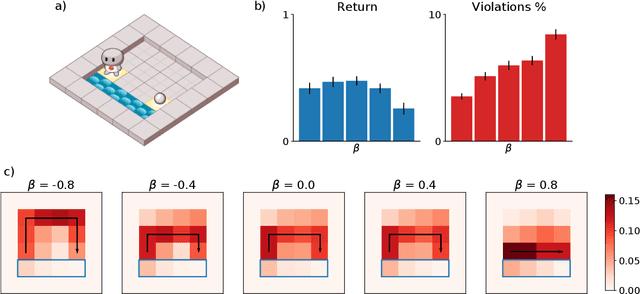

We extend temporal-difference (TD) learning in order to obtain risk-sensitive, model-free reinforcement learning algorithms. This extension can be regarded as modification of the Rescorla-Wagner rule, where the (sigmoidal) stimulus is taken to be either the event of over- or underestimating the TD target. As a result, one obtains a stochastic approximation rule for estimating the free energy from i.i.d. samples generated by a Gaussian distribution with unknown mean and variance. Since the Gaussian free energy is known to be a certainty-equivalent sensitive to the mean and the variance, the learning rule has applications in risk-sensitive decision-making.
* DeepMind Tech Report: 13 pages, 4 figures
View paper on