 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixSiam: A Mixture-based Approach to Self-supervised Representation Learning
Paper and Code
Nov 04, 2021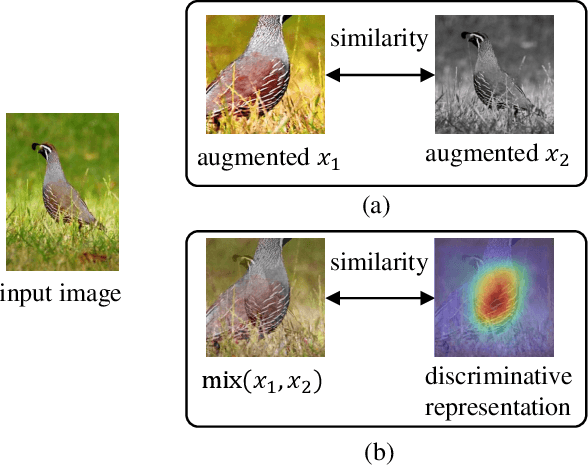
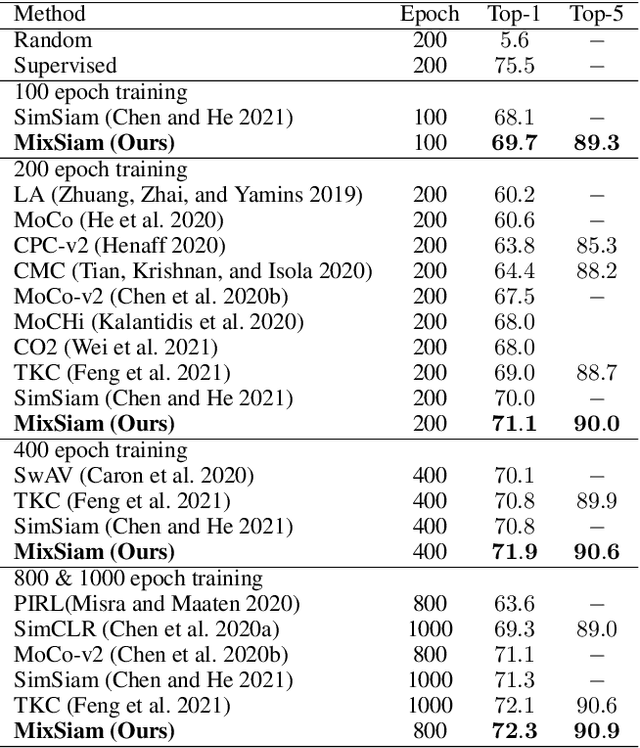
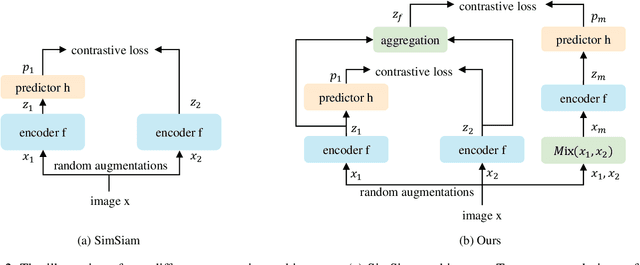
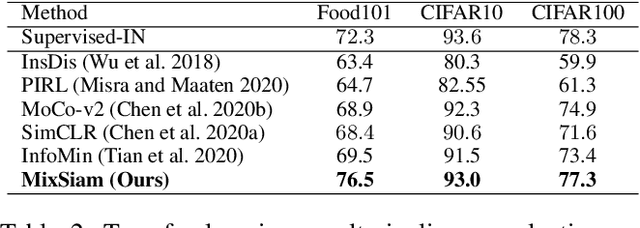
Recently contrastive learning has shown significant progress in learning visual representations from unlabeled data. The core idea is training the backbone to be invariant to different augmentations of an instance. While most methods only maximize the feature similarity between two augmented data, we further generate more challenging training samples and force the model to keep predicting discriminative representation on these hard samples. In this paper, we propose MixSiam, a mixture-based approach upon the traditional siamese network. On the one hand, we input two augmented images of an instance to the backbone and obtain the discriminative representation by performing an element-wise maximum of two features. On the other hand, we take the mixture of these augmented images as input, and expect the model prediction to be close to the discriminative representation. In this way, the model could access more variant data samples of an instance and keep predicting invariant discriminative representations for them. Thus the learned model is more robust compared to previous contrastive learning methods. Extensive experiments on large-scale datasets show that MixSiam steadily improves the baseline and achieves competitive results with state-of-the-art methods. Our code will be released soon.