 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Federated Learning with non-IID Data: Algorithm and System Design
Paper and Code
Oct 26, 2021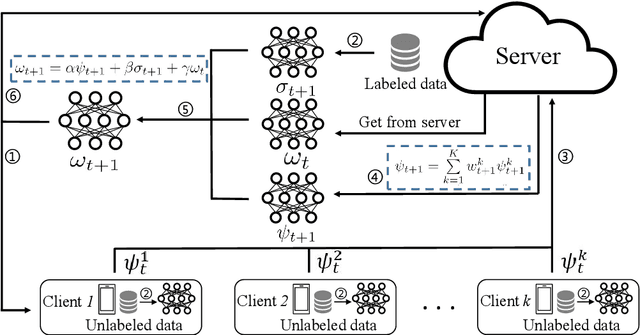
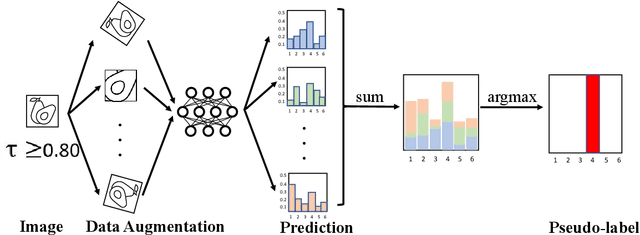
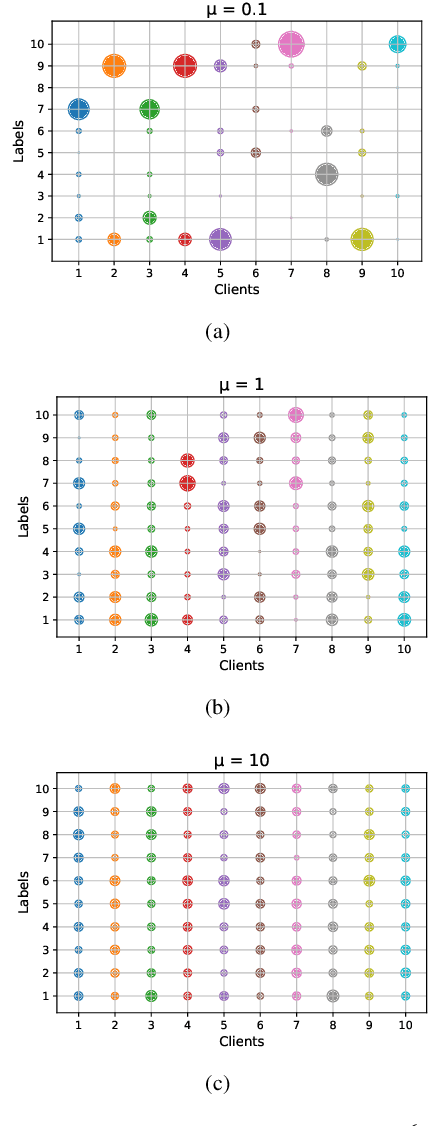
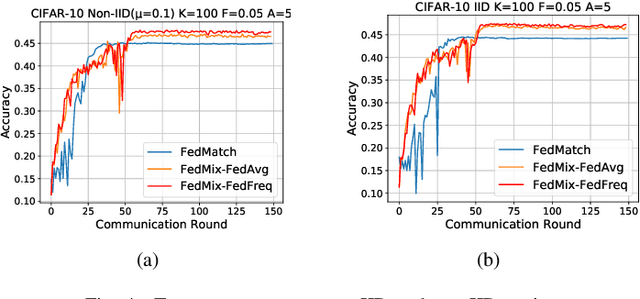
Federated Learning (FL) allows edge devices (or clients) to keep data locally while simultaneously training a shared high-quality global model. However, current research is generally based on an assumption that the training data of local clients have ground-truth. Furthermore, FL faces the challenge of statistical heterogeneity, i.e., the distribution of the client's local training data is non-independent identically distributed (non-IID). In this paper, we present a robust semi-supervised FL system design, where the system aims to solve the problem of data availability and non-IID in FL. In particular, this paper focuses on studying the labels-at-server scenario where there is only a limited amount of labeled data on the server and only unlabeled data on the clients. In our system design, we propose a novel method to tackle the problems, which we refer to as Federated Mixing (FedMix). FedMix improves the naive combination of FL and semi-supervised learning methods and designs parameter decomposition strategies for disjointed learning of labeled, unlabeled data, and global models. To alleviate the non-IID problem, we propose a novel aggregation rule based on the frequency of the client's participation in training, namely the FedFreq aggregation algorithm, which can adjust the weight of the corresponding local model according to this frequency. Extensive evaluations conducted on CIFAR-10 dataset show that the performance of our proposed method is significantly better than those of the current baseline. It is worth noting that our system is robust to different non-IID levels of client data.