 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternative Input Signals Ease Transfer in Multilingual Machine Translation
Paper and Code
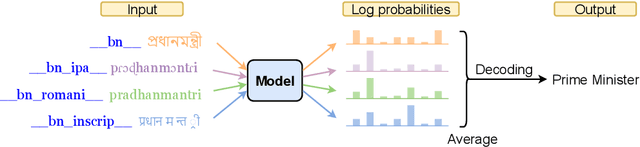
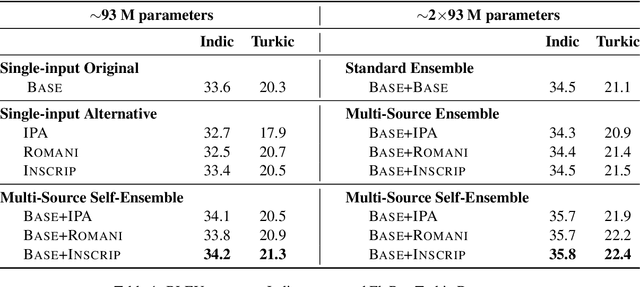
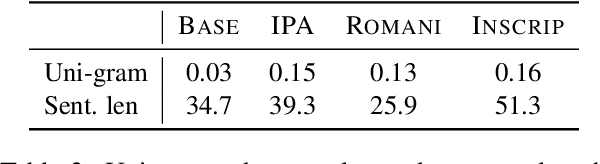
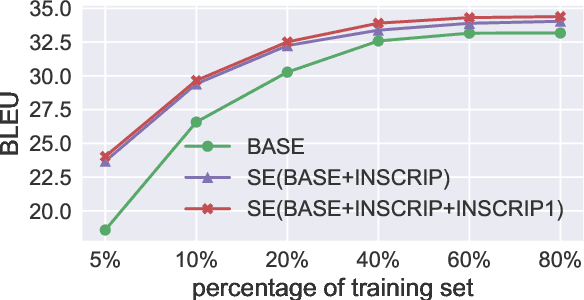
Recent work in multilingual machine translation (MMT) has focused on the potential of positive transfer between languages, particularly cases where higher-resourced languages can benefit lower-resourced ones. While training an MMT model, the supervision signals learned from one language pair can be transferred to the other via the tokens shared by multiple source languages. However, the transfer is inhibited when the token overlap among source languages is small, which manifests naturally when languages use different writing systems. In this paper, we tackle inhibited transfer by augmenting the training data with alternative signals that unify different writing systems, such as phonetic, romanized, and transliterated input. We test these signals on Indic and Turkic languages, two language families where the writing systems differ but languages still share common features. Our results indicate that a straightforward multi-source self-ensemble -- training a model on a mixture of various signals and ensembling the outputs of the same model fed with different signals during inference, outperforms strong ensemble baselines by 1.3 BLEU points on both language families. Further, we find that incorporating alternative inputs via self-ensemble can be particularly effective when training set is small, leading to +5 BLEU when only 5% of the total training data is accessible. Finally, our analysis demonstrates that including alternative signals yields more consistency and translates named entities more accurately, which is crucial for increased factuality of automated systems.