 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch Me A Video
Paper and Code
Oct 10, 2021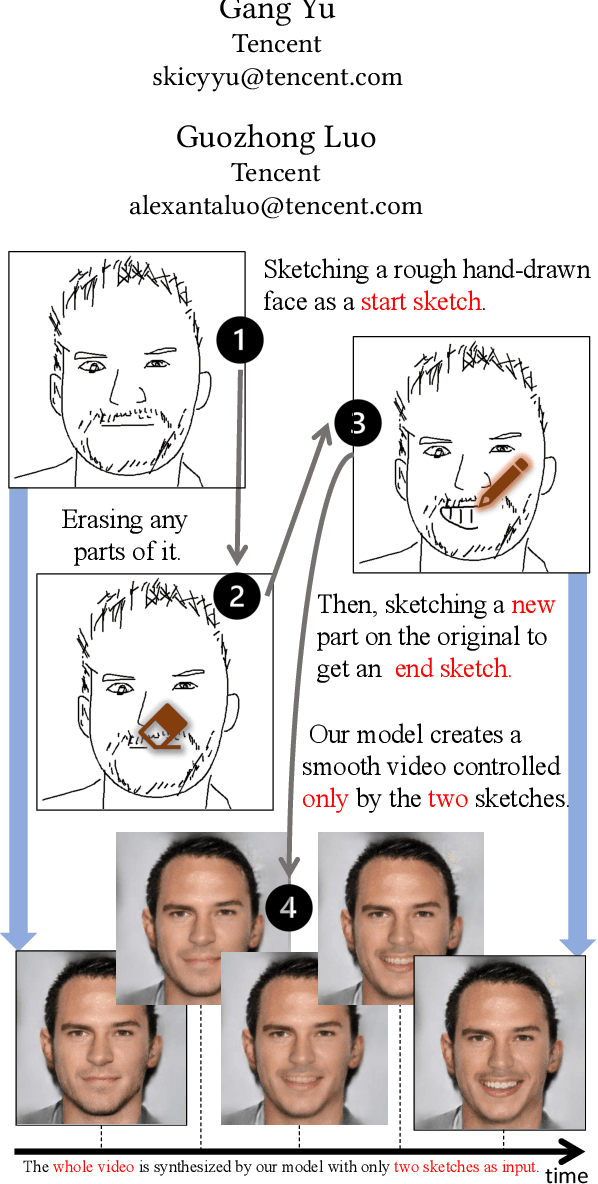
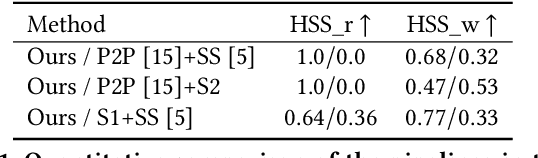
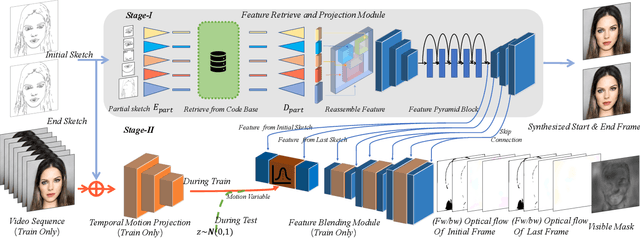

Video creation has been an attractive yet challenging task for artists to explore. With the advancement of deep learning, recent works try to utilize deep convolutional neural networks to synthesize a video with the aid of a guiding video, and have achieved promising results. However, the acquisition of guiding videos, or other forms of guiding temporal information is costly expensive and difficult in reality. Therefore, in this work we introduce a new video synthesis task by employing two rough bad-drwan sketches only as input to create a realistic portrait video. A two-stage Sketch-to-Video model is proposed, which consists of two key novelties: 1) a feature retrieve and projection (FRP) module, which parititions the input sketch into different parts and utilizes these parts for synthesizing a realistic start or end frame and meanwhile generating rich semantic features, is designed to alleviate the sketch out-of-domain problem due to arbitrarily drawn free-form sketch styles by different users. 2) A motion projection followed by feature blending module, which projects a video (used only in training phase) into a motion space modeled by normal distribution and blends the motion variables with semantic features extracted above, is proposed to alleviate the guiding temporal information missing problem in the test phase. Experiments conducted on a combination of CelebAMask-HQ and VoxCeleb2 dataset well validate that, our method can acheive both good quantitative and qualitative results in synthesizing high-quality videos from two rough bad-drawn sketches.