 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal ImageNet: How to discover spurious features in Deep Learning?
Paper and Code
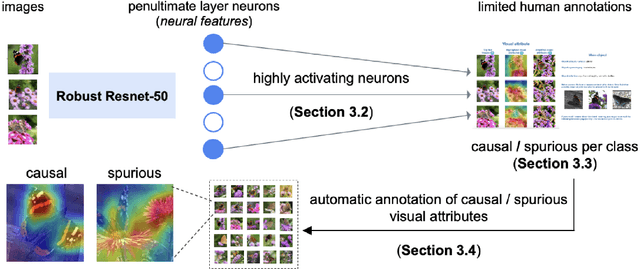

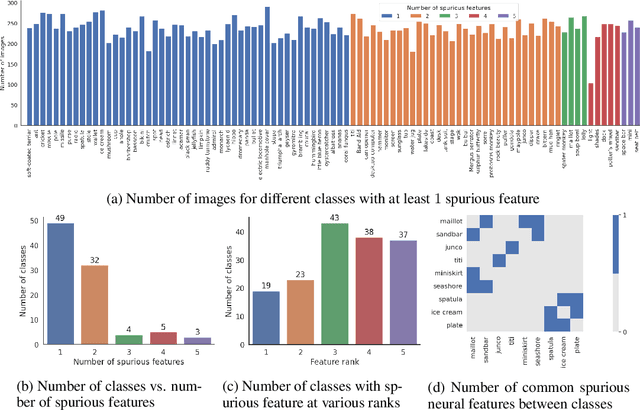
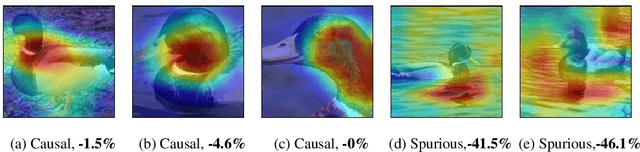
A key reason for the lack of reliability of deep neural networks in the real world is their heavy reliance on {\it spurious} input features that are causally unrelated to the true label. Focusing on image classifications, we define causal attributes as the set of visual features that are always a part of the object while spurious attributes are the ones that are likely to {\it co-occur} with the object but not a part of it (e.g., attribute ``fingers" for class ``band aid"). Traditional methods for discovering spurious features either require extensive human annotations (thus, not scalable), or are useful on specific models. In this work, we introduce a {\it scalable} framework to discover a subset of spurious and causal visual attributes used in inferences of a general model and localize them on a large number of images with minimal human supervision. Our methodology is based on this key idea: to identify spurious or causal \textit{visual attributes} used in model predictions, we identify spurious or causal \textit{neural features} (penultimate layer neurons of a robust model) via limited human supervision (e.g., using top 5 activating images per feature). We then show that these neural feature annotations {\it generalize} extremely well to many more images {\it without} any human supervision. We use the activation maps for these neural features as the soft masks to highlight spurious or causal visual attributes. Using this methodology, we introduce the {\it Causal Imagenet} dataset containing causal and spurious masks for a large set of samples from Imagenet. We assess the performance of several popular Imagenet models and show that they rely heavily on various spurious features in their predictions.