 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Multimedia Event Extraction from Video and Article
Paper and Code
Sep 27, 2021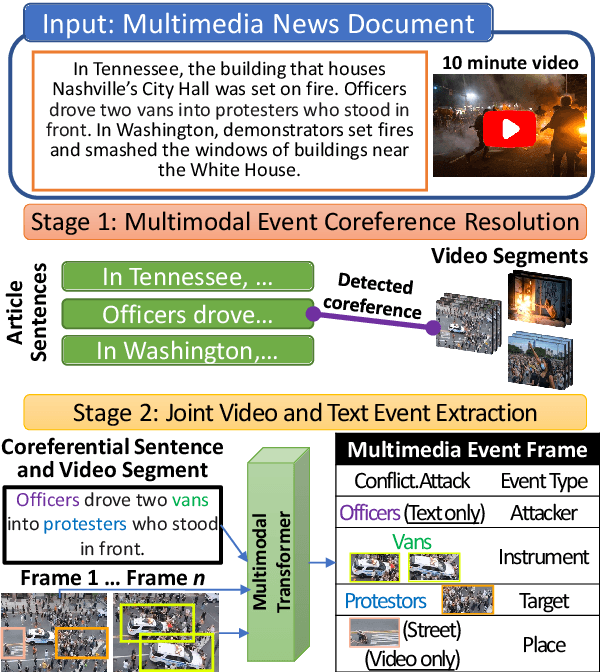


Visual and textual modalities contribute complementary information about events described in multimedia documents. Videos contain rich dynamics and detailed unfoldings of events, while text describes more high-level and abstract concepts. However, existing event extraction methods either do not handle video or solely target video while ignoring other modalities. In contrast, we propose the first approach to jointly extract events from video and text articles. We introduce the new task of Video MultiMedia Event Extraction (Video M2E2) and propose two novel components to build the first system towards this task. First, we propose the first self-supervised multimodal event coreference model that can determine coreference between video events and text events without any manually annotated pairs. Second, we introduce the first multimodal transformer which extracts structured event information jointly from both videos and text documents. We also construct and will publicly release a new benchmark of video-article pairs, consisting of 860 video-article pairs with extensive annotations for evaluating methods on this task. Our experimental results demonstrate the effectiveness of our proposed method on our new benchmark dataset. We achieve 6.0% and 5.8% absolute F-score gain on multimodal event coreference resolution and multimedia event extraction.