 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Finite-Horizon Restless Multi-Armed Multi-Action Bandits
Paper and Code
Sep 20, 2021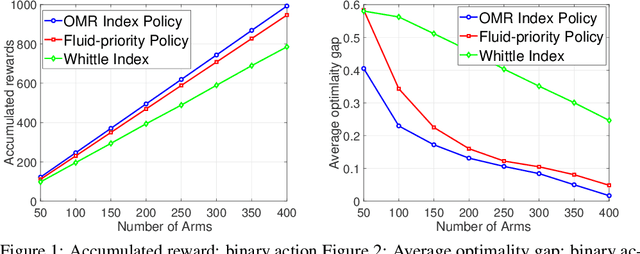
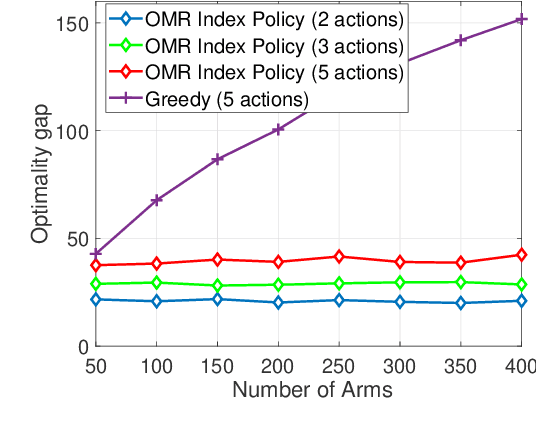
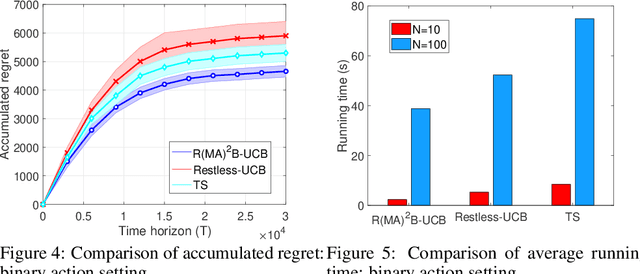
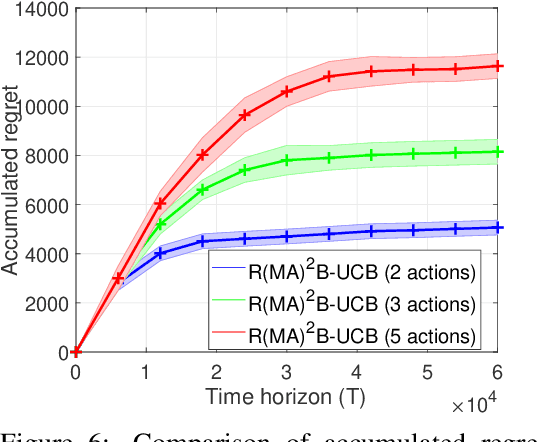
We study a finite-horizon restless multi-armed bandit problem with multiple actions, dubbed R(MA)^2B. The state of each arm evolves according to a controlled Markov decision process (MDP), and the reward of pulling an arm depends on both the current state of the corresponding MDP and the action taken. The goal is to sequentially choose actions for arms so as to maximize the expected value of the cumulative rewards collected. Since finding the optimal policy is typically intractable, we propose a computationally appealing index policy which we call Occupancy-Measured-Reward Index Policy. Our policy is well-defined even if the underlying MDPs are not indexable. We prove that it is asymptotically optimal when the activation budget and number of arms are scaled up, while keeping their ratio as a constant. For the case when the system parameters are unknown, we develop a learning algorithm. Our learning algorithm uses the principle of optimism in the face of uncertainty and further uses a generative model in order to fully exploit the structure of Occupancy-Measured-Reward Index Policy. We call it the R(MA)^2B-UCB algorithm. As compared with the existing algorithms, R(MA)^2B-UCB performs close to an offline optimum policy, and also achieves a sub-linear regret with a low computational complexity. Experimental results show that R(MA)^2B-UCB outperforms the existing algorithms in both regret and run time.