 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Crowdsourcing Protocols for Evaluating the Factual Consistency of Summaries
Paper and Code
Sep 21, 2021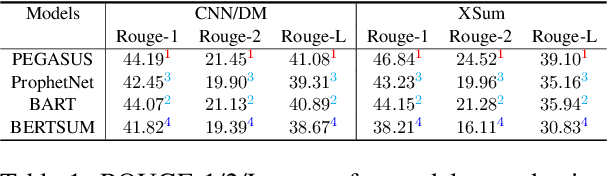
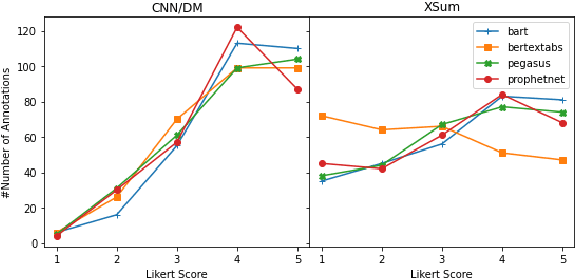
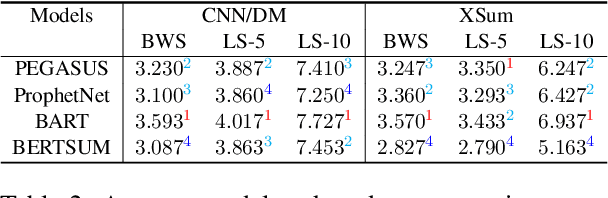
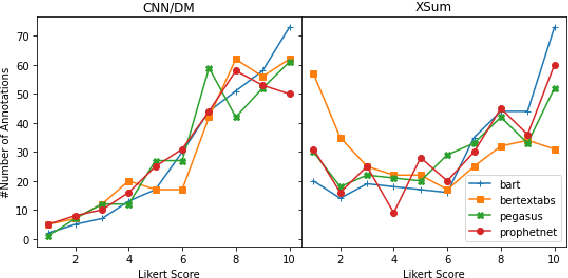
Current pre-trained models applied to summarization are prone to factual inconsistencies which either misrepresent the source text or introduce extraneous information. Thus, comparing the factual consistency of summaries is necessary as we develop improved models. However, the optimal human evaluation setup for factual consistency has not been standardized. To address this issue, we crowdsourced evaluations for factual consistency using the rating-based Likert scale and ranking-based Best-Worst Scaling protocols, on 100 articles from each of the CNN-Daily Mail and XSum datasets over four state-of-the-art models, to determine the most reliable evaluation framework. We find that ranking-based protocols offer a more reliable measure of summary quality across datasets, while the reliability of Likert ratings depends on the target dataset and the evaluation design. Our crowdsourcing templates and summary evaluations will be publicly available to facilitate future research on factual consistency in summarization.