 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanly Certifying Superhuman Classifiers
Paper and Code
Sep 16, 2021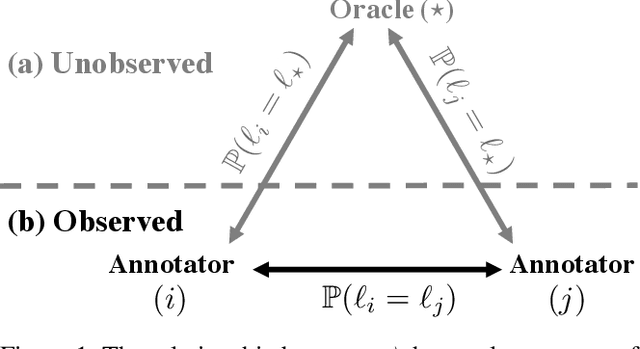

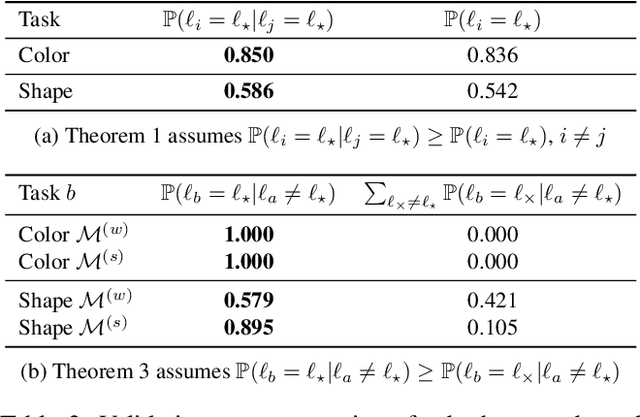
Estimating the performance of a machine learning system is a longstanding challenge in artificial intelligence research. Today, this challenge is especially relevant given the emergence of systems which appear to increasingly outperform human beings. In some cases, this "superhuman" performance is readily demonstrated; for example by defeating legendary human players in traditional two player games. On the other hand, it can be challenging to evaluate classification models that potentially surpass human performance. Indeed, human annotations are often treated as a ground truth, which implicitly assumes the superiority of the human over any models trained on human annotations. In reality, human annotators can make mistakes and be subjective. Evaluating the performance with respect to a genuine oracle may be more objective and reliable, even when querying the oracle is expensive or impossible. In this paper, we first raise the challenge of evaluating the performance of both humans and models with respect to an oracle which is unobserved. We develop a theory for estimating the accuracy compared to the oracle, using only imperfect human annotations for reference. Our analysis provides a simple recipe for detecting and certifying superhuman performance in this setting, which we believe will assist in understanding the stage of current research on classification. We validate the convergence of the bounds and the assumptions of our theory on carefully designed toy experiments with known oracles. Moreover, we demonstrate the utility of our theory by meta-analyzing large-scale natural language processing tasks, for which an oracle does not exist, and show that under our assumptions a number of models from recent years are with high probability superhuman.