 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation
Paper and Code
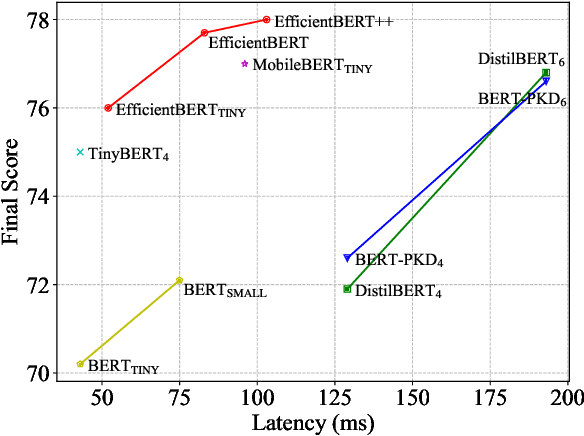

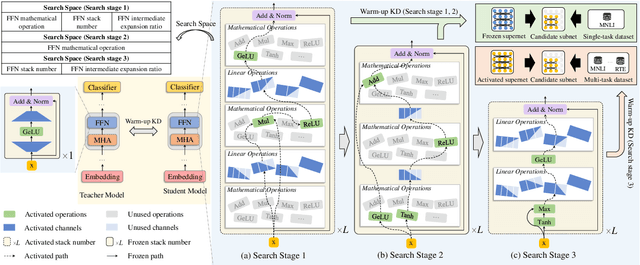
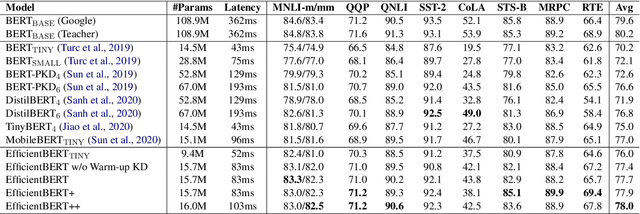
Pre-trained language models have shown remarkable results on various NLP tasks. Nevertheless, due to their bulky size and slow inference speed, it is hard to deploy them on edge devices. In this paper, we have a critical insight that improving the feed-forward network (FFN) in BERT has a higher gain than improving the multi-head attention (MHA) since the computational cost of FFN is 2$\sim$3 times larger than MHA. Hence, to compact BERT, we are devoted to designing efficient FFN as opposed to previous works that pay attention to MHA. Since FFN comprises a multilayer perceptron (MLP) that is essential in BERT optimization, we further design a thorough search space towards an advanced MLP and perform a coarse-to-fine mechanism to search for an efficient BERT architecture. Moreover, to accelerate searching and enhance model transferability, we employ a novel warm-up knowledge distillation strategy at each search stage. Extensive experiments show our searched EfficientBERT is 6.9$\times$ smaller and 4.4$\times$ faster than BERT$\rm_{BASE}$, and has competitive performances on GLUE and SQuAD Benchmarks. Concretely, EfficientBERT attains a 77.7 average score on GLUE \emph{test}, 0.7 higher than MobileBERT$\rm_{TINY}$, and achieves an 85.3/74.5 F1 score on SQuAD v1.1/v2.0 \emph{dev}, 3.2/2.7 higher than TinyBERT$_4$ even without data augmentation. The code is released at https://github.com/cheneydon/efficient-bert.