 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Language-specificity of Multilingual BERT and the Impact of Fine-tuning
Paper and Code
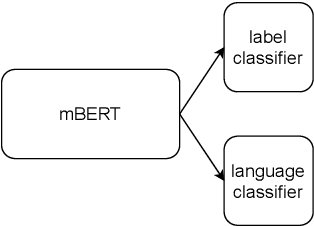
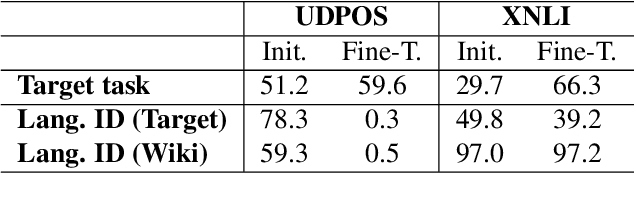
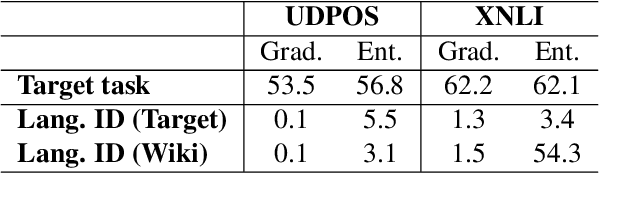

Recent work has shown evidence that the knowledge acquired by multilingual BERT (mBERT) has two components: a language-specific and a language-neutral one. This paper analyses the relationship between them, in the context of fine-tuning on two tasks -- POS tagging and natural language inference -- which require the model to bring to bear different degrees of language-specific knowledge. Visualisations reveal that mBERT loses the ability to cluster representations by language after fine-tuning, a result that is supported by evidence from language identification experiments. However, further experiments on 'unlearning' language-specific representations using gradient reversal and iterative adversarial learning are shown not to add further improvement to the language-independent component over and above the effect of fine-tuning. The results presented here suggest that the process of fine-tuning causes a reorganisation of the model's limited representational capacity, enhancing language-independent representations at the expense of language-specific ones.