 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Untrustworthy Samples: Data Filtering for Open-domain Dialogues with Bayesian Optimization
Paper and Code

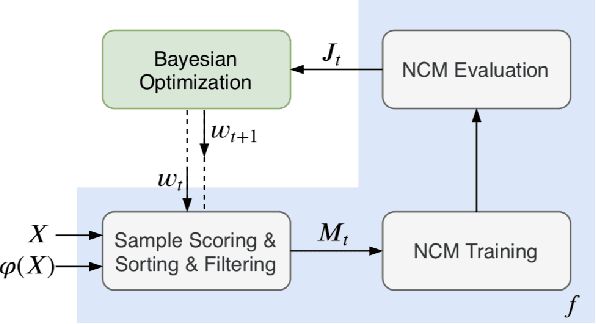
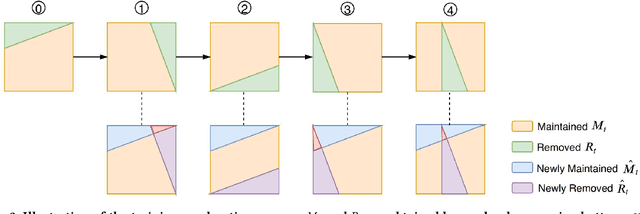
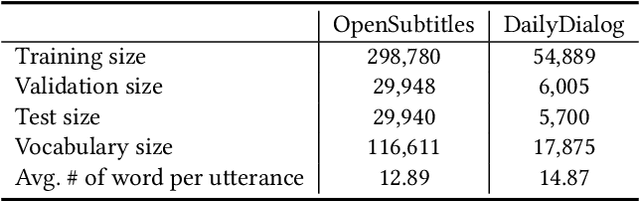
Being able to reply with a related, fluent, and informative response is an indispensable requirement for building high-quality conversational agents. In order to generate better responses, some approaches have been proposed, such as feeding extra information by collecting large-scale datasets with human annotations, designing neural conversational models (NCMs) with complex architecture and loss functions, or filtering out untrustworthy samples based on a dialogue attribute, e.g., Relatedness or Genericness. In this paper, we follow the third research branch and present a data filtering method for open-domain dialogues, which identifies untrustworthy samples from training data with a quality measure that linearly combines seven dialogue attributes. The attribute weights are obtained via Bayesian Optimization (BayesOpt) that aims to optimize an objective function for dialogue generation iteratively on the validation set. Then we score training samples with the quality measure, sort them in descending order, and filter out those at the bottom. Furthermore, to accelerate the "filter-train-evaluate" iterations involved in BayesOpt on large-scale datasets, we propose a training framework that integrates maximum likelihood estimation (MLE) and negative training method (NEG). The training method updates parameters of a trained NCMs on two small sets with newly maintained and removed samples, respectively. Specifically, MLE is applied to maximize the log-likelihood of newly maintained samples, while NEG is used to minimize the log-likelihood of newly removed ones. Experimental results on two datasets show that our method can effectively identify untrustworthy samples, and NCMs trained on the filtered datasets achieve better performance.