 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Faster Convergence of Scaled Sign Gradient Descent
Paper and Code
Sep 04, 2021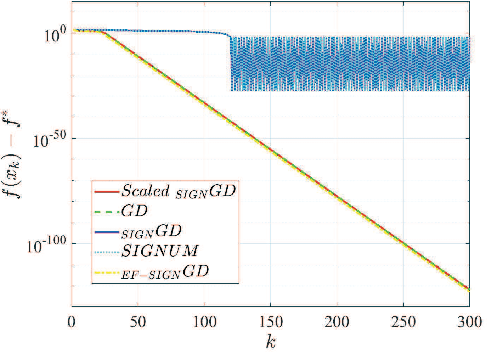
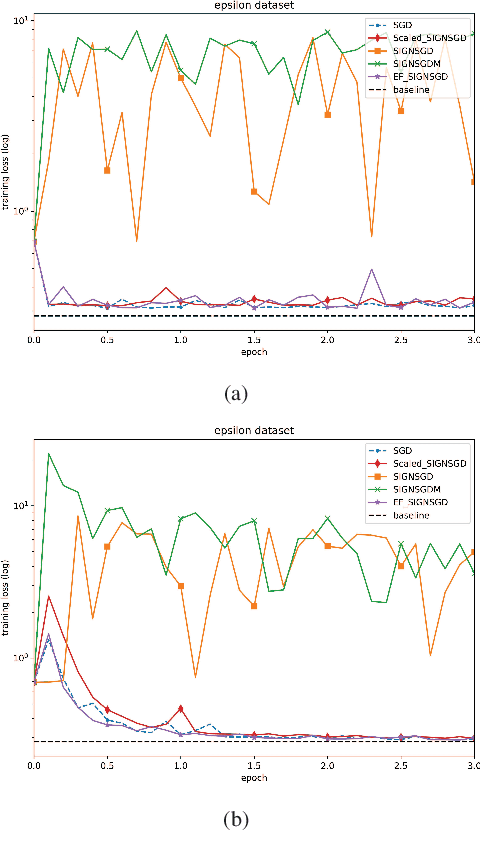
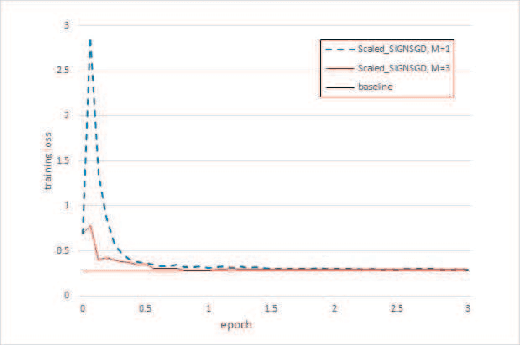
Communication has been seen as a significant bottleneck in industrial applications over large-scale networks. To alleviate the communication burden, sign-based optimization algorithms have gained popularity recently in both industrial and academic communities, which is shown to be closely related to adaptive gradient methods, such as Adam. Along this line, this paper investigates faster convergence for a variant of sign-based gradient descent, called scaled signGD, in three cases: 1) the objective function is strongly convex; 2) the objective function is nonconvex but satisfies the Polyak-Lojasiewicz (PL) inequality; 3) the gradient is stochastic, called scaled signGD in this case. For the first two cases, it can be shown that the scaled signGD converges at a linear rate. For case 3), the algorithm is shown to converge linearly to a neighborhood of the optimal value when a constant learning rate is employed, and the algorithm converges at a rate of $O(1/k)$ when using a diminishing learning rate, where $k$ is the iteration number. The results are also extended to the distributed setting by majority vote in a parameter-server framework. Finally, numerical experiments on logistic regression are performed to corroborate the theoretical findings.