 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of approaches to improve worst-case predictive model performance over patient subpopulations
Paper and Code
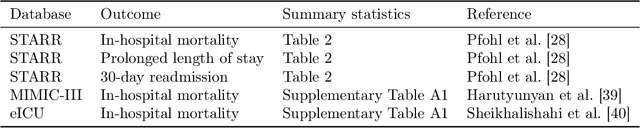
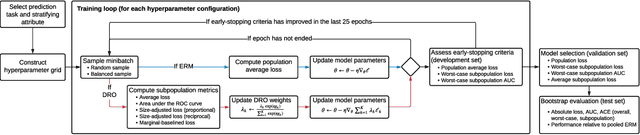
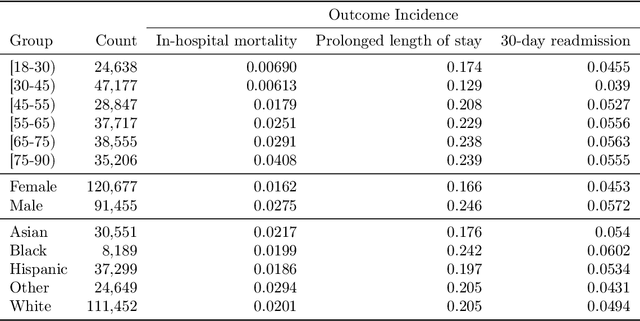
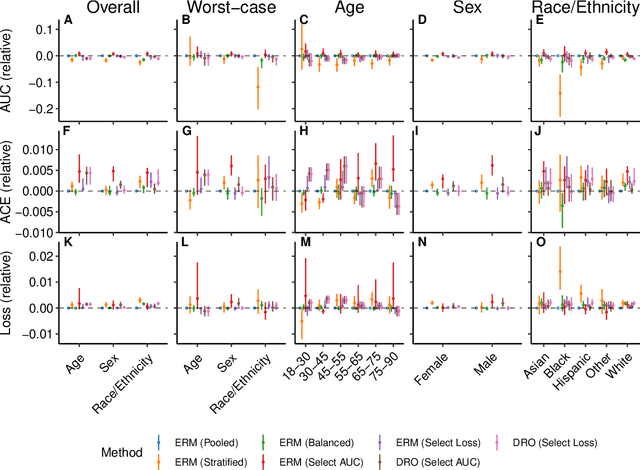
Predictive models for clinical outcomes that are accurate on average in a patient population may underperform drastically for some subpopulations, potentially introducing or reinforcing inequities in care access and quality. Model training approaches that aim to maximize worst-case model performance across subpopulations, such as distributionally robust optimization (DRO), attempt to address this problem without introducing additional harms. We conduct a large-scale empirical study of DRO and several variations of standard learning procedures to identify approaches for model development and selection that consistently improve disaggregated and worst-case performance over subpopulations compared to standard approaches for learning predictive models from electronic health records data. In the course of our evaluation, we introduce an extension to DRO approaches that allows for specification of the metric used to assess worst-case performance. We conduct the analysis for models that predict in-hospital mortality, prolonged length of stay, and 30-day readmission for inpatient admissions, and predict in-hospital mortality using intensive care data. We find that, with relatively few exceptions, no approach performs better, for each patient subpopulation examined, than standard learning procedures using the entire training dataset. These results imply that when it is of interest to improve model performance for patient subpopulations beyond what can be achieved with standard practices, it may be necessary to do so via techniques that implicitly or explicitly increase the effective sample size.