 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
Paper and Code
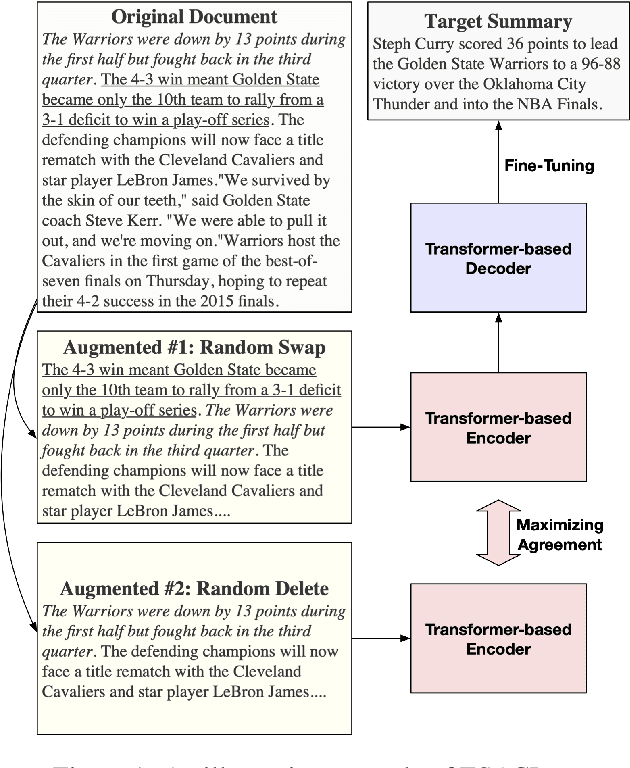
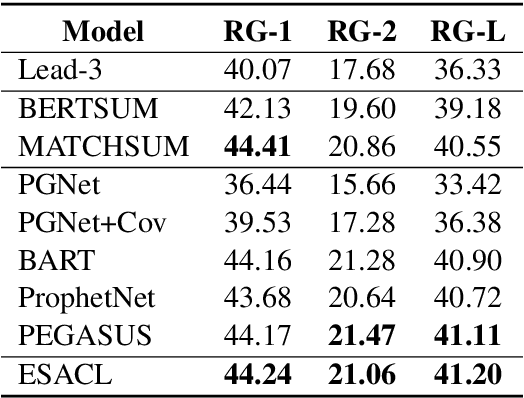
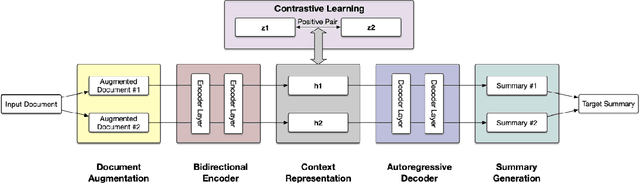
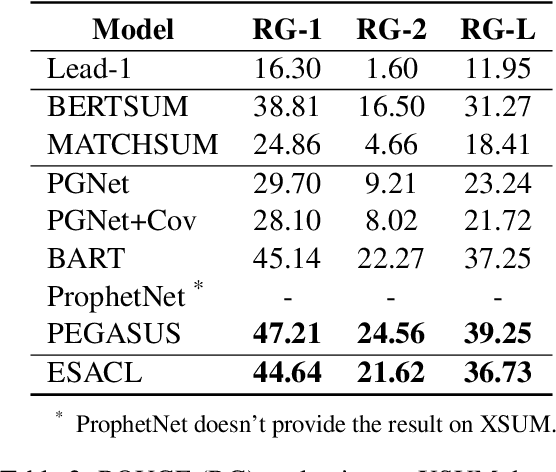
In this paper, we present a denoising sequence-to-sequence (seq2seq) autoencoder via contrastive learning for abstractive text summarization. Our model adopts a standard Transformer-based architecture with a multi-layer bi-directional encoder and an auto-regressive decoder. To enhance its denoising ability, we incorporate self-supervised contrastive learning along with various sentence-level document augmentation. These two components, seq2seq autoencoder and contrastive learning, are jointly trained through fine-tuning, which improves the performance of text summarization with regard to ROUGE scores and human evaluation. We conduct experiments on two datasets and demonstrate that our model outperforms many existing benchmarks and even achieves comparable performance to the state-of-the-art abstractive systems trained with more complex architecture and extensive computation resources.