 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Knowledge Augmented Text Visual Question Answering
Paper and Code
Aug 22, 2021
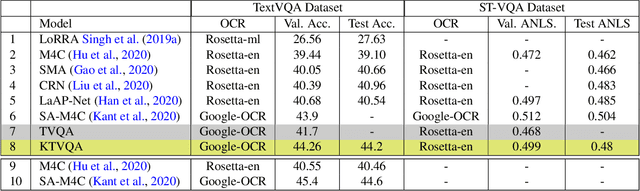
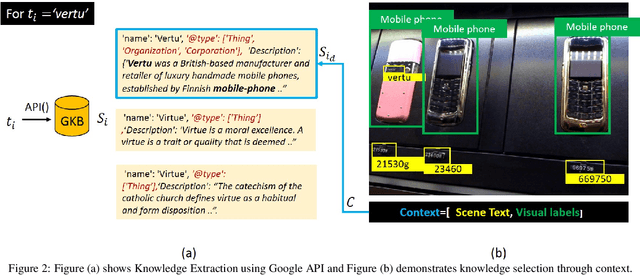
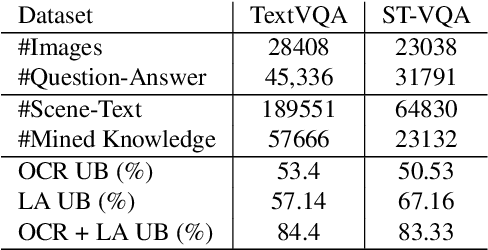
The open-ended question answering task of Text-VQA requires reading and reasoning about local, often previously unseen, scene-text content of an image to generate answers. In this work, we propose the generalized use of external knowledge to augment our understanding of the said scene-text. We design a framework to extract, filter, and encode knowledge atop a standard multimodal transformer for vision language understanding tasks. Through empirical evidence, we demonstrate how knowledge can highlight instance-only cues and thus help deal with training data bias, improve answer entity type correctness, and detect multiword named entities. We generate results comparable to the state-of-the-art on two publicly available datasets, under the constraints of similar upstream OCR systems and training data.