 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation of VHR EO Images using Unsupervised Learning
Paper and Code
Aug 10, 2021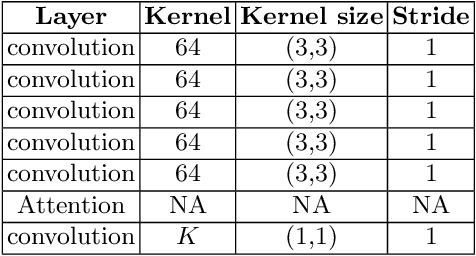
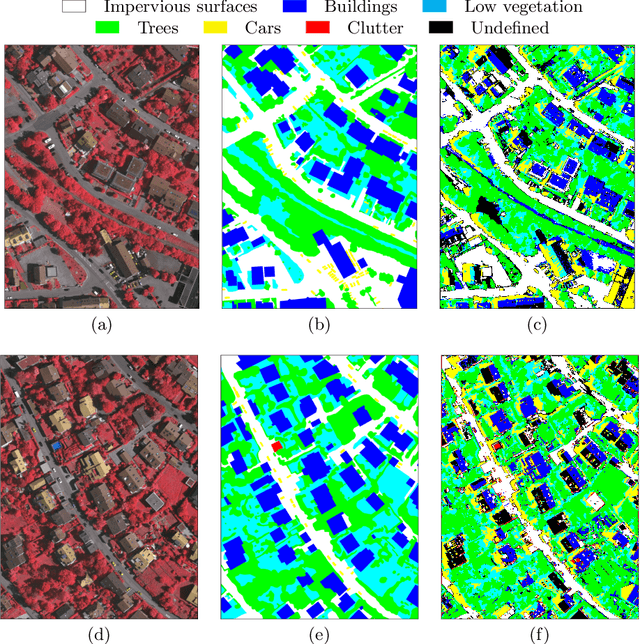
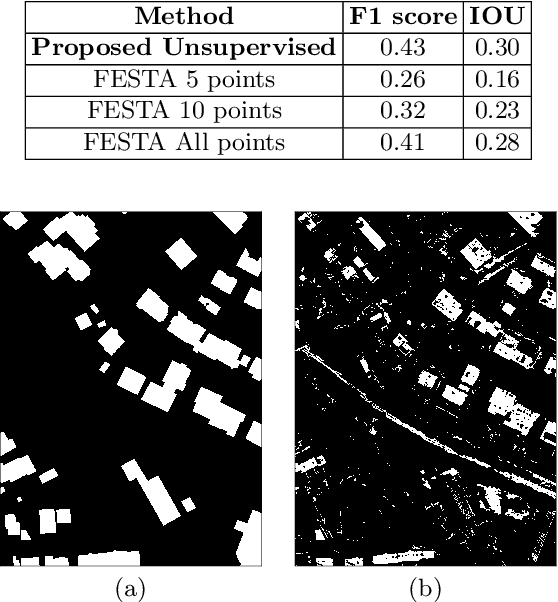
Semantic segmentation is a crucial step in many Earth observation tasks. Large quantity of pixel-level annotation is required to train deep networks for semantic segmentation. Earth observation techniques are applied to varieties of applications and since classes vary widely depending on the applications, therefore, domain knowledge is often required to label Earth observation images, impeding availability of labeled training data in many Earth observation applications. To tackle these challenges, in this paper we propose an unsupervised semantic segmentation method that can be trained using just a single unlabeled scene. Remote sensing scenes are generally large. The proposed method exploits this property to sample smaller patches from the larger scene and uses deep clustering and contrastive learning to refine the weights of a lightweight deep model composed of a series of the convolution layers along with an embedded channel attention. After unsupervised training on the target image/scene, the model automatically segregates the major classes present in the scene and produces the segmentation map. Experimental results on the Vaihingen dataset demonstrate the efficacy of the proposed method.