Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Perturbed Length-aware Positional Encoding for Non-autoregressive Neural Machine Translation
Paper and Code

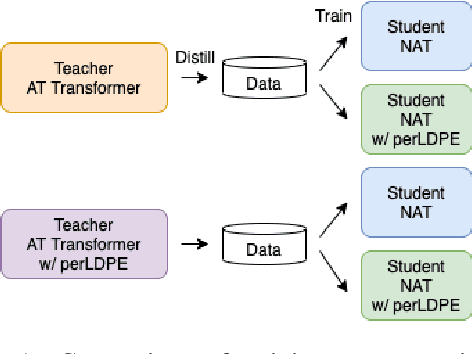
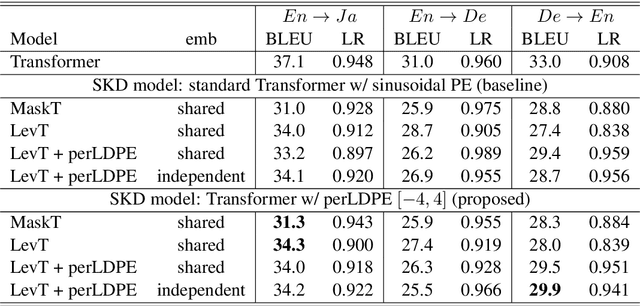
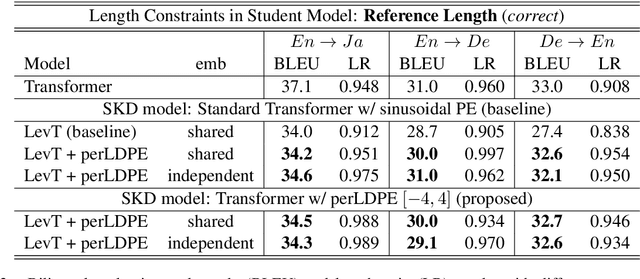
Non-autoregressive neural machine translation (NAT) usually employs sequence-level knowledge distillation using autoregressive neural machine translation (AT) as its teacher model. However, a NAT model often outputs shorter sentences than an AT model. In this work, we propose sequence-level knowledge distillation (SKD) using perturbed length-aware positional encoding and apply it to a student model, the Levenshtein Transformer. Our method outperformed a standard Levenshtein Transformer by 2.5 points in bilingual evaluation understudy (BLEU) at maximum in a WMT14 German to English translation. The NAT model output longer sentences than the baseline NAT models.
* 5 pages, 1 figures. Will be presented at ACL SRW 2021
View paper on