 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Probabilistic Logic and Deep Learning for Self-Supervised Learning
Paper and Code
Jul 27, 2021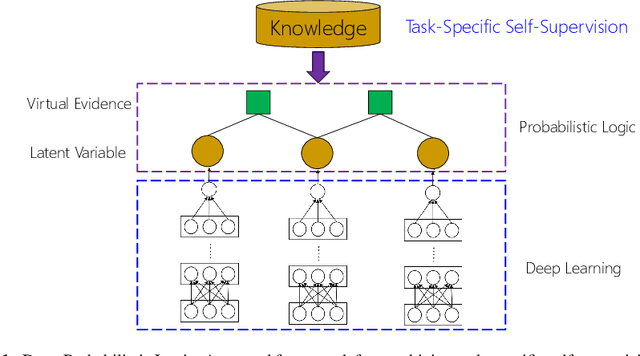
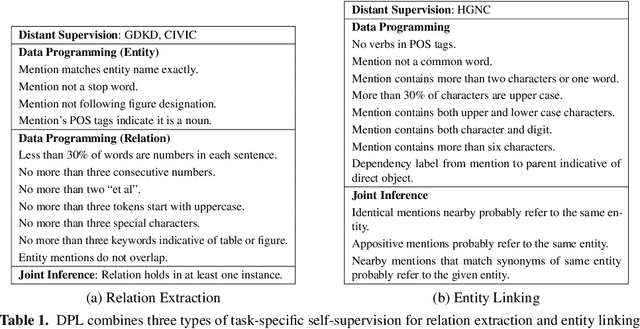
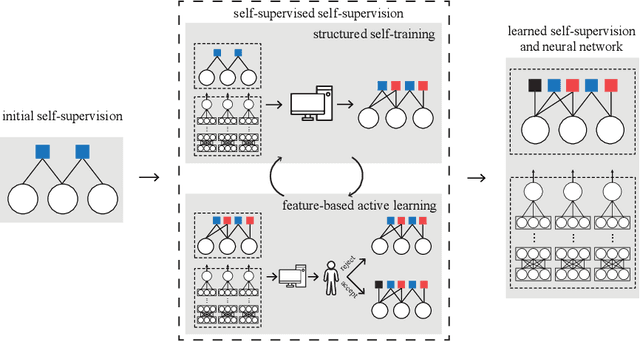
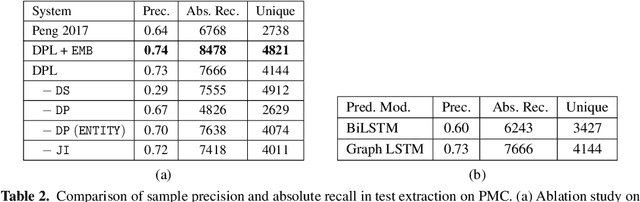
Deep learning has proven effective for various application tasks, but its applicability is limited by the reliance on annotated examples. Self-supervised learning has emerged as a promising direction to alleviate the supervision bottleneck, but existing work focuses on leveraging co-occurrences in unlabeled data for task-agnostic representation learning, as exemplified by masked language model pretraining. In this chapter, we explore task-specific self-supervision, which leverages domain knowledge to automatically annotate noisy training examples for end applications, either by introducing labeling functions for annotating individual instances, or by imposing constraints over interdependent label decisions. We first present deep probabilistic logic(DPL), which offers a unifying framework for task-specific self-supervision by composing probabilistic logic with deep learning. DPL represents unknown labels as latent variables and incorporates diverse self-supervision using probabilistic logic to train a deep neural network end-to-end using variational EM. Next, we present self-supervised self-supervision(S4), which adds to DPL the capability to learn new self-supervision automatically. Starting from an initial seed self-supervision, S4 iteratively uses the deep neural network to propose new self supervision. These are either added directly (a form of structured self-training) or verified by a human expert (as in feature-based active learning). Experiments on real-world applications such as biomedical machine reading and various text classification tasks show that task-specific self-supervision can effectively leverage domain expertise and often match the accuracy of supervised methods with a tiny fraction of human effort.